高性能网络模型 Reactor Proactor
阅读数:126 评论数:0
跳转到新版页面分类
架构学
正文
一、概述
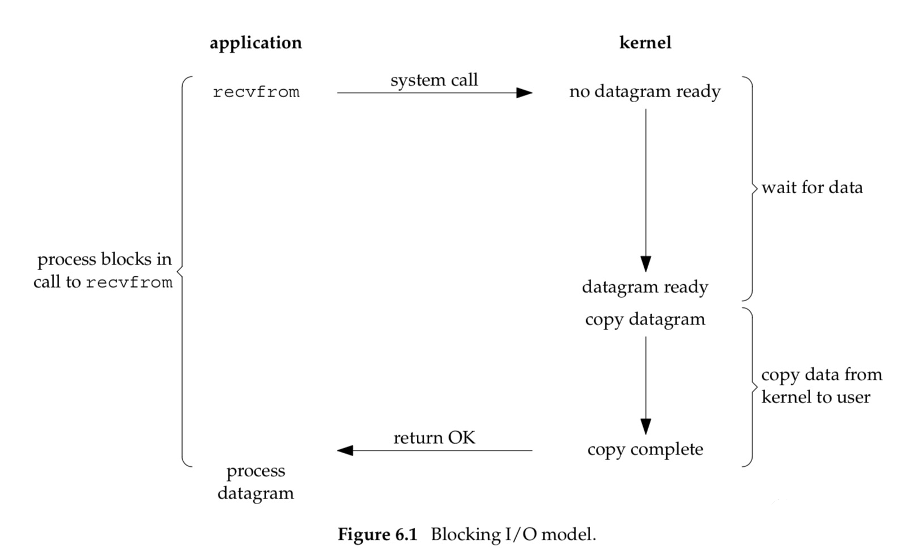
当应用程序调用recvfrom系统调用时,该操作将导致进程阻塞。等待内核通过中断等一系列操作将网络数据拷贝到内核态(Socket缓冲区),再将内核态数据拷贝到用户态的内存。这种方式只能通过一个线程来管理一个连接,一般需要采用多线程方式来处理请求。需要大量线程来维护网络连接,并且线程频繁进行上下文切换,导致性能低下。
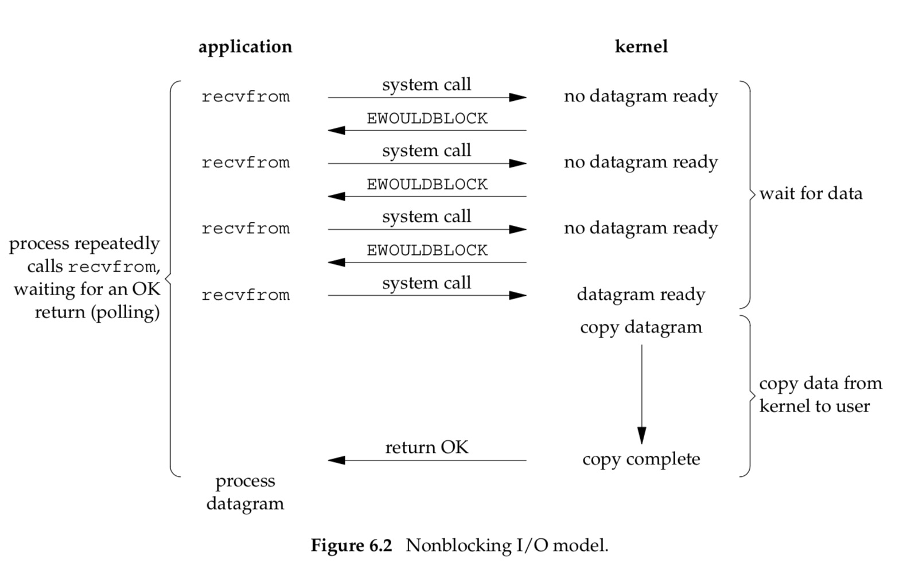
非阻塞IO,用户进程调用recvfrom时,立即返回结果。不会阻塞。优点是:不像阻塞IO,调用接口会阻塞,可以使用一个线程来管理多个网络连接。缺点是:进程需要不断轮训调用内核接口,导致大量的系统调用和cpu资源。
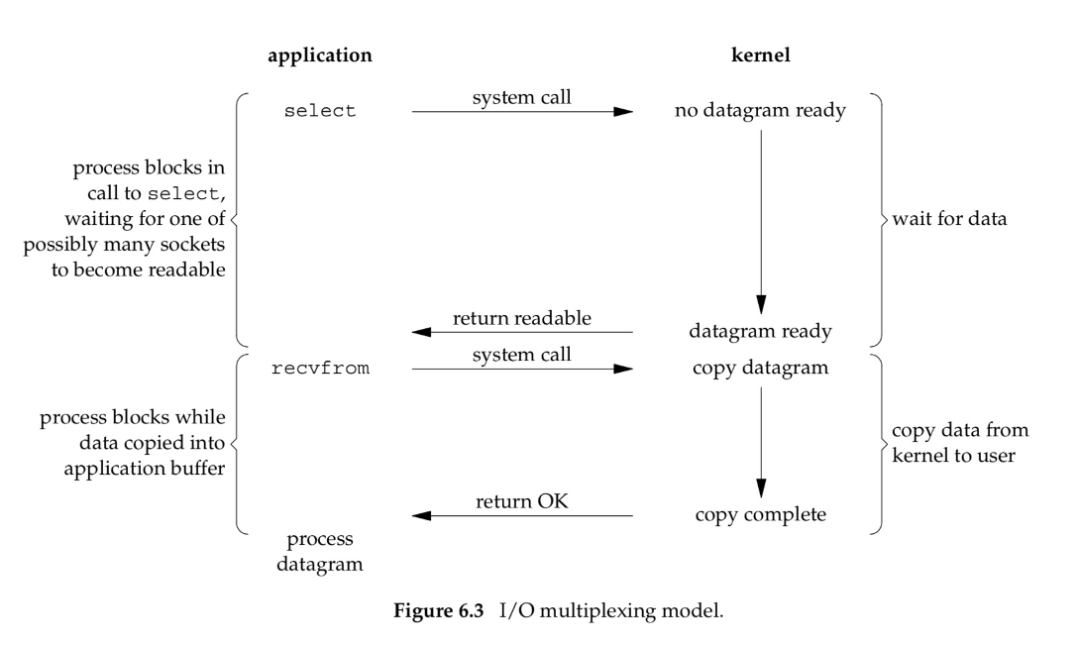
一次调用可以监听多个Socket连接,它可以看作是NIO的一种实现技术。
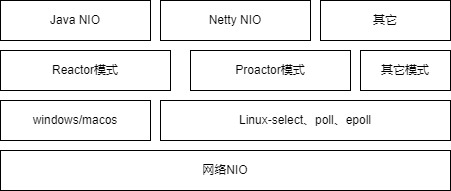
这时如何从服务的很多连接中快速找到有IO事件发生socket?Linux内核提供的IO多路复用方案是:select、poll、epoll。
应用层在内核的IO多路复用基础上进一步封装,出现了易于使用的两种高性能网络模型:Reactor模式和Proactor模式。
二、linux的socket
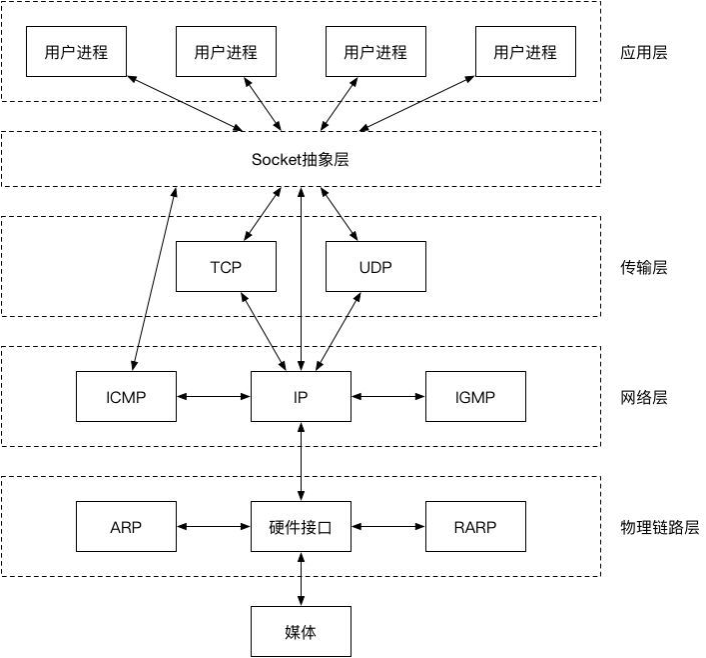
Socket是内核提供给应用层的一层抽象,能够通过使用简单的api来进行数据读写。在Linux系统中,一切皆文件。Socket也是一类文件,我们可以像使用普通文件一样,对其进行open、read、write、close等操作。程序是通过fd来访问对应的Socket。
一个socket对应主要包括了四元组(源ip、源port、目标ip、目标port)、接收队列、发送队列、等待队列(进程)。
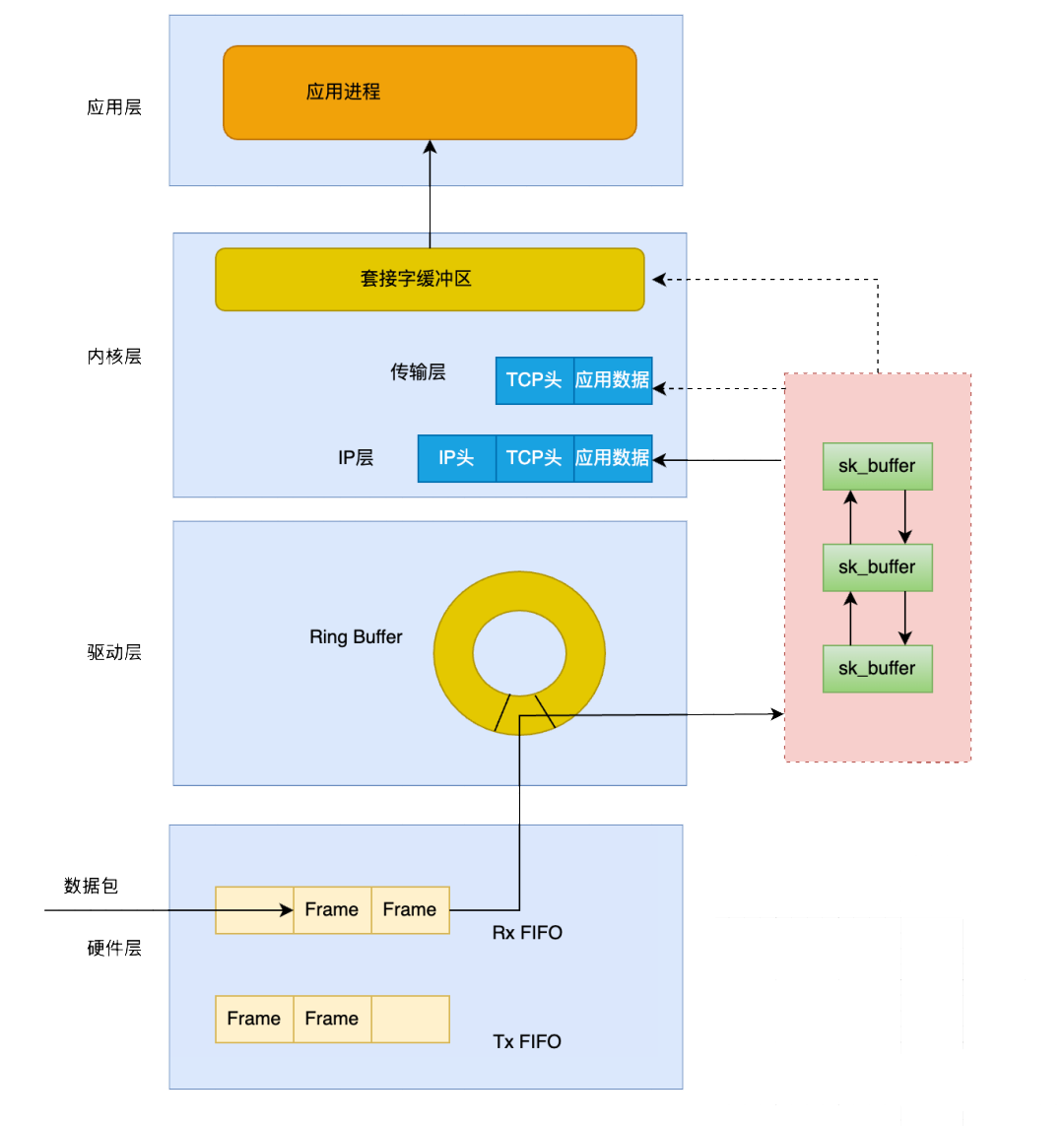
(1)数据包进入网卡的接收队列
(2)网卡通过DMA机制将数据复制到内核缓冲区
(3)复制完成后向系统发送中断请求,内核会把数据包转换成skb格式,交由tcp/ip协议栈处理。
(4)协议栈一层一层进行拆包头处理,此处sk_buffer设计比较巧妙,为了性能,只是指针的移动。
(5)在传输层会去除源 IP、源端口、目的 IP、目的端口,获取到对应的socket,从而将数据拷贝到socket缓冲区。
(6)内核唤醒用户进程,用户进程就可以通过read从socket缓冲区读取数据。
三、Linux IO多路复用
在Linux系统中,一切皆文件。Socket也是一类文件,我们可以像使用普通文件一样,对其进行open、read、write、close等操作。程序是通过fd来访问对应的Socket。
int select(
int nfds, // 监控的文件描述符集里最大文件描述符加1
fd_set *readfds, // 监控有读数据到达文件描述符集合,引用类型的参数
fd_set *writefds, // 监控写数据到达文件描述符集合,引用类型的参数
fd_set *exceptfds, // 监控异常发生达文件描述符集合,引用类型的参数
struct timeval *timeout); // 定时阻塞监控时间readfds、writefds、errorfds 是三个文件描述符集合。select 会遍历每个集合的前 nfds 个描述符,分别找到可以读取、可以写入、发生错误的描述符,统称为“就绪”的描述符。
(1)fd_set
由于文件描述符 fd 是一个从 0 开始的无符号整数,所以可以使用 fd_set 的二进制每一位来表示一个文件描述符。某一位为 1,表示对应的文件描述符已就绪。比如比如设 fd_set 长度为 1 字节,则一个 fd_set 变量最大可以表示 8 个文件描述符。当 select 返回 fd_set = 00010011 时,表示文件描述符 1、2、5 已经就绪。
(2)select的缺点
| 性能开销大 |
1、调用 select 时会陷入内核,这时需要将参数中的 fd_set 从用户空间拷贝到内核空间,select 执行完后,还需要将 fd_set 从内核空间拷贝回用户空间,高并发场景下这样的拷贝会消耗极大资源;(epoll 优化为不拷贝) 2、进程被唤醒后,不知道哪些连接已就绪即收到了数据,需要遍历传递进来的所有 fd_set 的每一位,不管它们是否就绪;(epoll 优化为异步事件通知) 3、select 只返回就绪文件的个数,具体哪个文件可读还需要遍历;(epoll 优化为只返回就绪的文件描述符,无需做无效的遍历) |
| 同时能够监听的文件描述符数量太少 | 受限于 sizeof(fd_set) 的大小,在编译内核时就确定了且无法更改。一般是 32 位操作系统是 1024,64 位是 2048。(poll、epoll 优化为适应链表方式) |
(3)服务端使用select监控多个连接的C代码
#define MAXCLINE 5 // 连接队列中的个数
int fd[MAXCLINE]; // 连接的文件描述符队列
int main(void)
{
sock_fd = socket(AF_INET,SOCK_STREAM,0) // 建立主机间通信的 socket 结构体
.....
bind(sock_fd, (struct sockaddr *)&server_addr, sizeof(server_addr); // 绑定socket到当前服务器
listen(sock_fd, 5); // 监听 5 个TCP连接
fd_set fdsr; // bitmap类型的文件描述符集合,01100 表示第1、2位有数据到达
int max;
for(i = 0; i < 5; i++)
{
.....
fd[i] = accept(sock_fd, (struct sockaddr *)&client_addr, &sin_size); // 跟 5 个客户端依次建立 TCP 连接,并将连接放入 fd 文件描述符队列
}
while(1) // 循环监听连接上的数据是否到达
{
FD_ZERO(&fdsr); // 对 fd_set 即 bitmap 类型进行复位,即全部重置为0
for(i = 0; i < 5; i++)
{
FD_SET(fd[i], &fdsr); // 将要监听的TCP连接对应的文件描述符所在的bitmap的位置置1,比如 0110010110 表示需要监听第 1、2、5、7、8个文件描述符对应的 TCP 连接
}
ret = select(max + 1, &fdsr, NULL, NULL, NULL); // 调用select系统函数进入内核检查哪个连接的数据到达
for(i=0;i<5;i++)
{
if(FD_ISSET(fd[i], &fdsr)) // fd_set中为1的位置表示的连接,意味着有数据到达,可以让用户进程读取
{
ret = recv(fd[i], buf,sizeof(buf), 0);
......
}
}
}和 select 类似,只是描述 fd 集合的方式不同,poll 使用 pollfd 结构而非 select 的 fd_set 结构。
struct pollfd {
int fd; // 要监听的文件描述符
short events; // 要监听的事件
short revents; // 文件描述符fd上实际发生的事件
};管理多个描述符也是进行轮询,根据描述符的状态进行处理,但 poll 无最大文件描述符数量的限制,因其基于链表存储。
select 和 poll 在内部机制方面并没有太大的差异。相比于 select 机制,poll 只是取消了最大监控文件描述符数限制,并没有从根本上解决 select 存在的问题。
epoll 是对 select 和 poll 的改进,解决了“性能开销大”和“文件描述符数量少”这两个缺点,是性能最高的多路复用实现方式,能支持的并发量也是最大。
(1)特点
| 使用红黑树存储一份文件描述符集合,每个文件描述符只需在添加时传入一次,无需用户每次都重新传入;—— 解决了 select 中 fd_set 重复拷贝到内核的问题 |
| 通过异步 IO 事件找到就绪的文件描述符,而不是通过轮询的方式; |
| 使用队列存储就绪的文件描述符,且会按需返回就绪的文件描述符,无须再次遍历; |
(2)epoll的基本用法
int main(void)
{
struct epoll_event events[5];
int epfd = epoll_create(10); // 创建一个 epoll 对象
......
for(i = 0; i < 5; i++)
{
static struct epoll_event ev;
.....
ev.data.fd = accept(sock_fd, (struct sockaddr *)&client_addr, &sin_size);
ev.events = EPOLLIN;
epoll_ctl(epfd, EPOLL_CTL_ADD, ev.data.fd, &ev); // 向 epoll 对象中添加要管理的连接
}
while(1)
{
nfds = epoll_wait(epfd, events, 5, 10000); // 等待其管理的连接上的 IO 事件
for(i=0; i<nfds; i++)
{
......
read(events[i].data.fd, buff, MAXBUF)
}
}
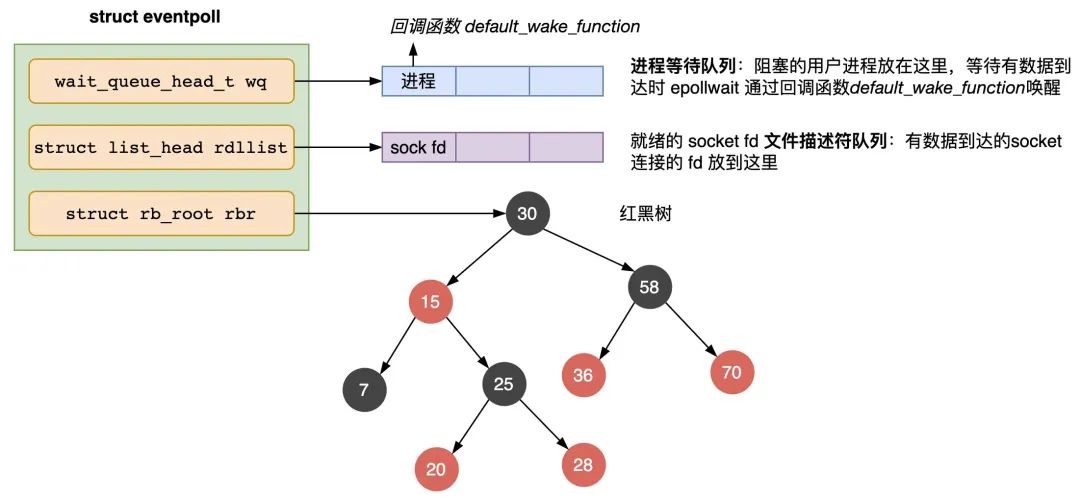
}epoll_create 函数会创建一个 struct eventpoll 的内核对象,类似 socket,把它关联到当前进程的已打开文件列表中。
struct eventpoll {
wait_queue_head_t wq; // 等待队列链表,存放阻塞的进程
struct list_head rdllist; // 数据就绪的文件描述符都会放到这里
struct rb_root rbr; // 红黑树,管理用户进程下添加进来的所有 socket 连接
......
}
主要负责把服务端和客户端建立的 socket 连接注册到 eventpoll 对象里。
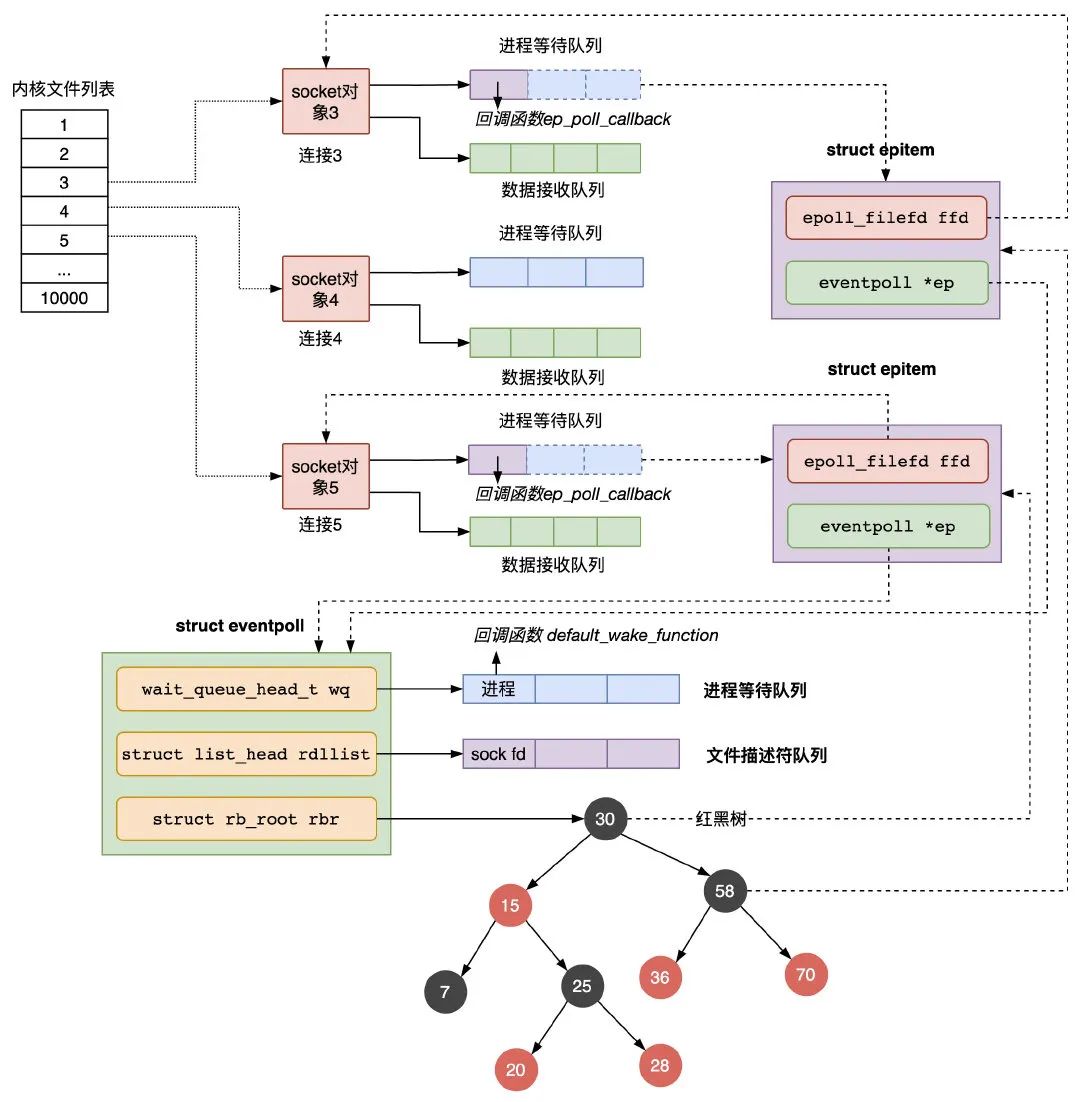
| epitem | 主要包含两个字段,分别存放 socket fd 即连接的文件描述符,和所属的 eventpoll 对象的指针; |
epoll_wait 函数的动作比较简单,检查 eventpoll 对象的就绪的连接 rdllist 上是否有数据到达,如果没有就把当前的进程描述符添加到一个等待队列项里,加入到 eventpoll 的进程等待队列里,然后阻塞当前进程,等待数据到达时通过回调函数被唤醒。
当 eventpoll 监控的连接上有数据到达时,通过下面几个步骤唤醒对应的进程处理数据:
| 1 |
socket 的数据接收队列有数据到达,会通过进程等待队列的回调函数 ep_poll_callback 找到红黑树中的节点 epitem; |
| 2 | ep_poll_callback 函数将有数据到达的 epitem 添加到 eventpoll 对象的就绪队列 rdllist 中; |
| 3 | ep_poll_callback 函数检查 eventpoll 对象的进程等待队列上是否有等待项,通过回调函数 default_wake_func 唤醒这个进程,进行数据的处理; |
| 4 | 当进程醒来后,继续从 epoll_wait 时暂停的代码继续执行,把 rdlist 中就绪的事件返回给用户进程,让用户进程调用 recv 把已经到达内核 socket 等待队列的数据拷贝到用户空间使用。 |
四、Reactor模式
Reactor模式,用于把多个请求分发给多个处理器,基本思想是“分而治之+事件驱动”。
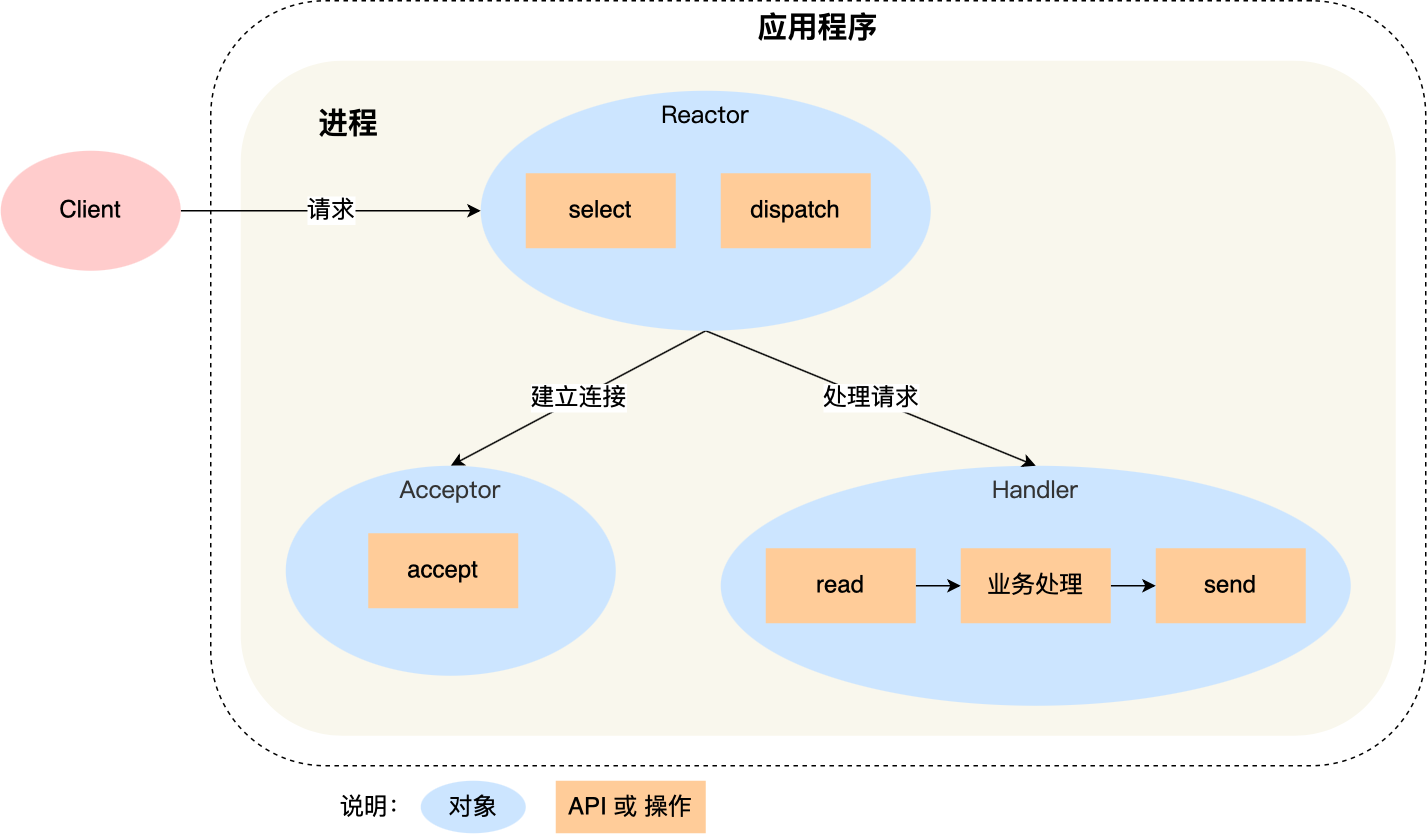
| Reactor | 作用是监听和分发事件; |
| Acceptor | 作用是获取连接 |
| Handler | 作用是处理业务; |
(1)Reactor 对象通过 select (IO 多路复用接口) 监听事件,收到事件后通过 dispatch 进行分发,具体分发给 Acceptor 对象还是 Handler 对象,还要看收到的事件类型;
(2)如果是连接建立的事件,则交由 Acceptor 对象进行处理,Acceptor 对象会通过 accept 方法 获取连接,并创建一个 Handler 对象来处理后续的响应事件;
(3)如果不是连接建立事件, 则交由当前连接对应的 Handler 对象来进行响应;
单 Reactor 单进程的方案因为全部工作都在同一个进程内完成,所以实现起来比较简单,不需要考虑进程间通信,也不用担心多进程竞争。
但是,这种方案存在 2 个缺点:
| 1 | 因为只有一个进程,无法充分利用 多核 CPU 的性能; |
| 2 | Handler 对象在业务处理时,整个进程是无法处理其他连接的事件的,如果业务处理耗时比较长,那么就造成响应的延迟; |
Redis 6.0 版本之前采用的正是「单 Reactor 单进程」的方案,因为 Redis 业务处理主要是在内存中完成,操作的速度是很快的,性能瓶颈不在 CPU 上,所以 Redis 对于命令的处理是单进程的方案。
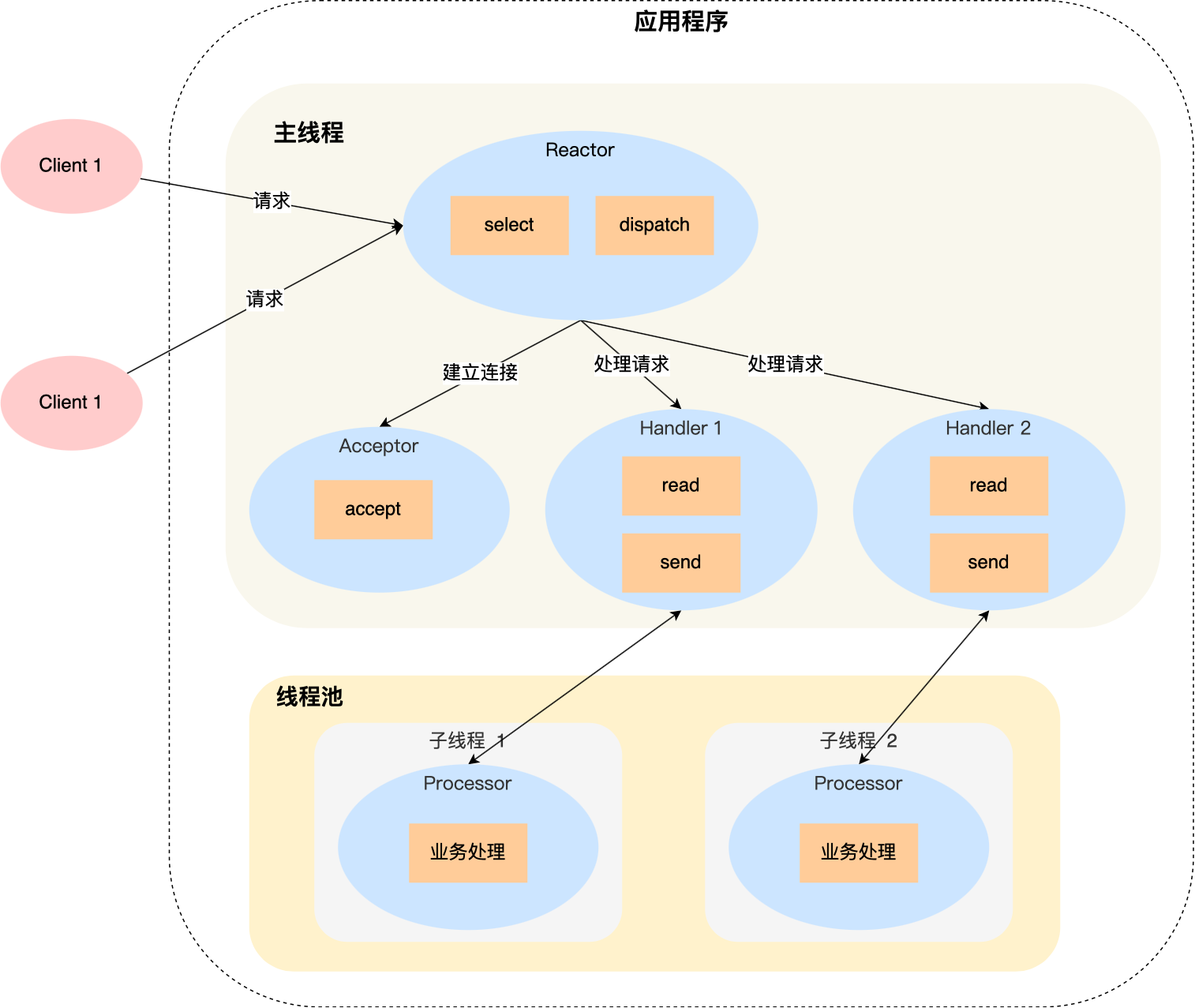
与单Reactor单线程的区别:
| 1 | Handler 对象不再负责业务处理,只负责数据的接收和发送,Handler 对象通过 read 读取到数据后,会将数据发给子线程里的 Processor 对象进行业务处理; |
| 2 | 子线程里的 Processor 对象就进行业务处理,处理完后,将结果发给主线程中的 Handler 对象,接着由 Handler 通过 send 方法将响应结果发送给 client; |
单 Reator 多线程的方案优势在于能够充分利用多核 CPU 的能,那既然引入多线程,那么自然就带来了多线程竞争资源的问题。
「单 Reactor」的模式还有个问题,因为一个 Reactor 对象承担所有事件的监听和响应,而且只在主线程中运行,在面对瞬间高并发的场景时,容易成为性能的瓶颈的地方。
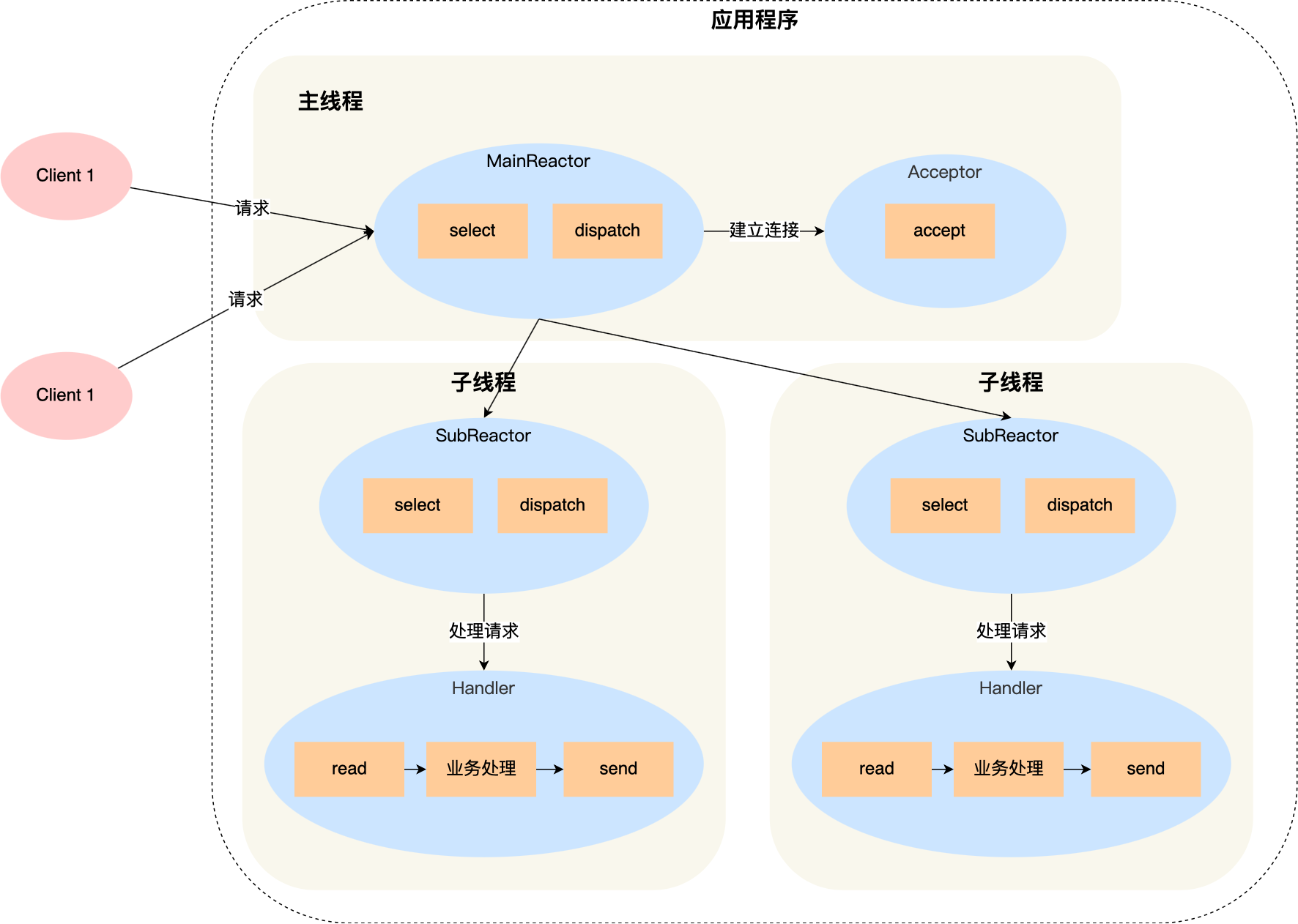
| 1 | 主线程中的 MainReactor 对象通过 select 监控连接建立事件,收到事件后通过 Acceptor 对象中的 accept 获取连接,将新的连接分配给某个子线程; |
| 2 | 子线程中的 SubReactor 对象将 MainReactor 对象分配的连接加入 select 继续进行监听,并创建一个 Handler 用于处理连接的响应事件。 |
| 3 | 如果有新的事件发生时,SubReactor 对象会调用当前连接对应的 Handler 对象来进行响应。 |
| 4 | Handler 对象通过 read -> 业务处理 -> send 的流程来完成完整的业务流程。 |
多 Reactor 多线程的方案虽然看起来复杂的,但是实际实现时比单 Reactor 多线程的方案要简单的多,原因如下:
| 1 | 主线程和子线程分工明确,主线程只负责接收新连接,子线程负责完成后续的业务处理。 |
| 2 | 主线程和子线程的交互很简单,主线程只需要把新连接传给子线程,子线程无须返回数据,直接就可以在子线程将处理结果发送给客户端。 |
Netty 和 Memcache 都采用了「多 Reactor 多线程」的方案。
五、Proactor模式 AIO(Asynchronous-Non-Blocking-IO)
| Reactor | 在每次感知到有事件发生(比如可读就绪事件)后,就需要应用进程主动调用 read 方法来完成数据的读取,也就是要应用进程主动将 socket 接收缓存中的数据读到应用进程内存中,这个过程是同步的,读取完数据后应用进程才能处理数据。 |
| Proactor | 在发起异步读写请求时,需要传入数据缓冲区的地址(用来存放结果数据)等信息,这样系统内核才可以自动帮我们把数据的读写工作完成,这里的读写工作全程由操作系统来做,并不需要像 Reactor 那样还需要应用进程主动发起 read/write 来读写数据,操作系统完成读写工作后,就会通知应用进程直接处理数据。 |
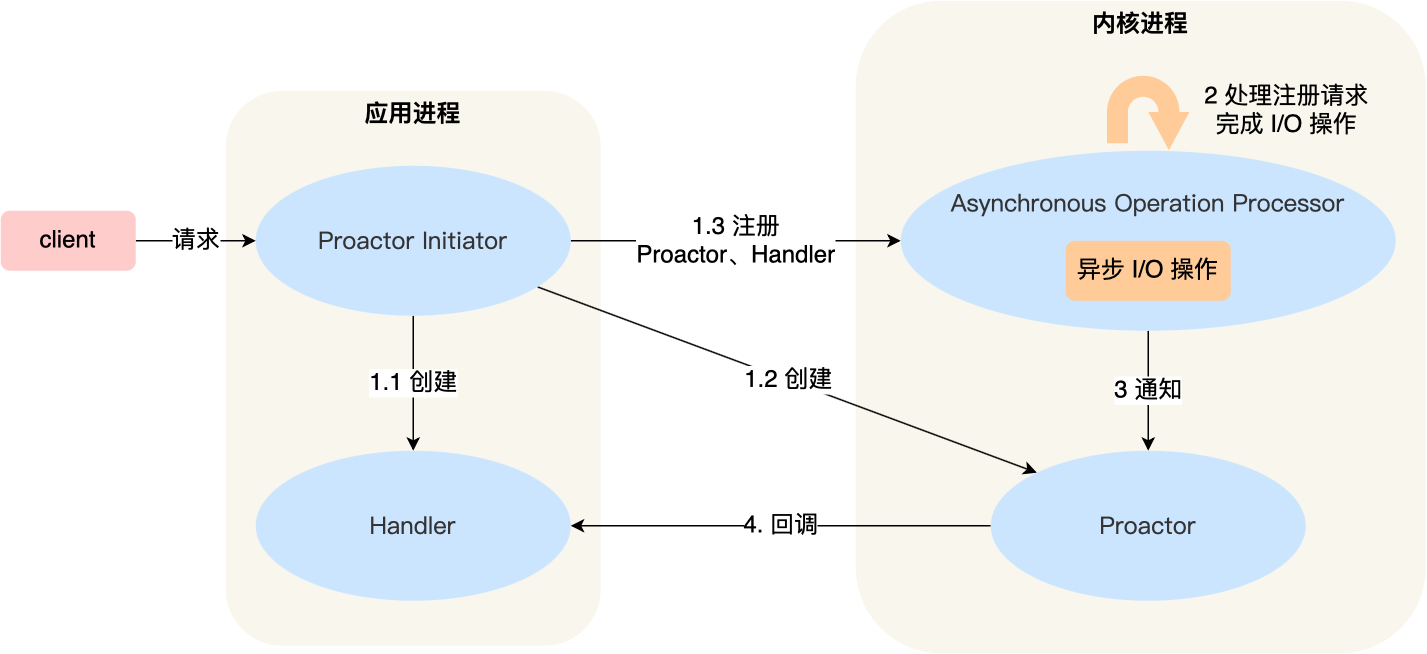
可惜的是,在 Linux 下的异步 I/O 是不完善的, aio 系列函数是由 POSIX 定义的异步操作接口,不是真正的操作系统级别支持的,而是在用户空间模拟出来的异步,并且仅仅支持基于本地文件的 aio 异步操作,网络编程中的 socket 是不支持的,这也使得基于 Linux 的高性能网络程序都是使用 Reactor 方案。
而 Windows 里实现了一套完整的支持 socket 的异步编程接口,这套接口就是 IOCP,是由操作系统级别实现的异步 I/O,真正意义上异步 I/O,因此在 Windows 里实现高性能网络程序可以使用效率更高的 Proactor 方案。