mysql优化explain、show profiles、show processlist、慢查询日志
阅读数:140 评论数:0
跳转到新版页面分类
数据库
正文
一、explain
explain能解释mysql如何处理SQL语句,表的加载顺序,表是如何连接,以及索引使用情况。是SQL优化的重要工具
上面语句的输出结果非常 类似于describe table或show columns from table。
只要在select语句前面加上单词加上单词explain即可,下面解释一个输出内容
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: test
partitions: NULL
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 4
filtered: 100.00
Extra: NULL
id相同,执行顺序从上到下,id不同,执行顺序从大到小。
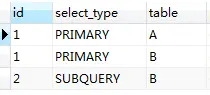
可以这样理解,执行顺序从大到小,先执行id为2的,然后执行id为1的(先A再B,规则1)。
| 类型 | 描述 |
| simple | 简单的select,不使用union和子查询 |
| primary |
查询中包含任何复杂的子部分,最外层的select被标记为PRIMARY |
| union | 联合后的第二查询 |
| dependent union | 一般是子查询中的第二个select语句 |
| union result |
union查询的结果 |
| subquery |
子查询中的第一个select |
| dependent subquery | 内部子查询,根据主查询而定(也就是一个关联子查询) |
| derived | 在from子句中使用的子查询 |
| uncached subquery | 一个结果无法缓存的子查询,必须重新查每行 |
| uncached unioin | 一个union中的第二或后一个select属于一个非缓存子查询 |



用于查询所需要表
解释了表在查询的关联中如使用。这个字段是我们优化要重点关注的字段,这个字段直接反映我们SQL的性能是否高效。
性能由好到差依次为:system>const>eq_ref>ref>range>index>all(一定要牢记)
| 类型 | 描述 |
| system | 表只有一行记录,这个是const的特例,一般不会出现,可以忽略 |
| const | 表示通过索引一次就找到了,const用于比较primary key或者unique索引。因为只匹配一行数据,所以很快。 |
| eq_ref |
对来自关联中其他表的每组行,从该表读取一行。条件是一对一关联
|
| fulltext | 使用fulltext索引执行关联 |
| ref | 对来自关联中其他表的每组行,从该表读取一组。条件是一对多关联 |
| ref_or_null | 类似ref查询,但是也查询为null行 |
| index_merge | 特定的优化 |
| unique_subquery | 关联查询可以返回一个唯一行的in子查询中代替ref |
| index_subquery | 类似unique_subquery,但是用作索引非唯一子查询 |
| range | 检索给定范围的行,一般条件查询中出现了>、<、in、between等查询 |
| index | 遍历索引树。通常比ALL快,因为索引文件通常比数据文件小。all和index都是读全表,但index是从索引中检索的,而all是从硬盘中检索的。 |
| all | 表中的每一行将被扫描 |
大致找到所需记录需要读取的行数。
(6)possible_keys
显示可能应用在这张表中的索引,但不一定被查询实际使用
(7)key
实际使用的索引。
(8)key_len
表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度。一般来说,索引长度越长表示精度越高,效率偏低;长度越短,效率高,但精度就偏低。并不是真正使用索引的长度,是个预估值。
(9)ref
表示哪一列被使用了,常数表示这一列等于某个常数
告诉我们连接是如何执行的,以及其他信息
| 值 | 意义 |
| distinct | 找到第一个匹配行后,停止查找 |
| not exists | 查询已经用left join优化 |
| range checked for each record | 试图找到要使用的最佳 索引,如果有这些的索引的话 |
| using filesort | 使用外部的索引排序,而不是按照表内的索引顺序进行读取。(一般需要优化) |
| using index | 表中所有信息来自索引 |
| using join buffer | 使用联合缓冲执行操作 |
| using temporary | 使用了临时表保存中间结果。常见于排序order by和分组查询group by(最好优化) |
| using where | 选择行时使用where子句 |
3、实际使用
可以用多种方法解决explain结果中出现的问题。
(1)检查列类型并且确认它们相同,如果列类型不同(列宽度),索引不能用于匹配这些列
(2)用关联优化器检查关键字的分布
在系统中执行
myisamchk --analyze pathtomysqldatabase/table
或者对多个表进行检查
myisamchk --analyze pathtomysqldatabase/*.MYI
或对所有数据库的所有表
myisamchk --analyze pathtomysqldir/*/*.MYI在mysql监视器中
analyze table tablename;(3)还可以考虑添加新索引,比如possible_keys列包含一些NULL值
二、show profiles
是MySQL提供的可以用来分析当前会话中语句执行的资源消耗情况的工具,可以用于sql调优的测量。默认是处于关闭状态的,会保存最近15次的运行结果。
1、查看状态
show variables like 'profiling';
2、开启动能
set profiling = 'on';
3、运行要观察的sql
show profiles;
除了执行时长,我们还可以查看cpu、io等情况
show profile cpu, block io for query query_id;
可以看到,查出来的结果就涵盖了sql执行过程中的整个生命周期,从校验权限、打开表开始,一直到查询结束,cleaning up。每个过程的cpu和io情况都对应的展示出来了。上面我们查询的字段是cpu和block io,那还有其它:
| column | description |
|---|---|
| all | 所有的开销信息 |
| block io | 块io相关开销信息 |
| context switches | 上下文切换相关开销信息 |
| cpu | cpu相关开销信息 |
| ipc | 发送和接收相关开销信息 |
| memory | 内存相关开销信息 |
| page faults | 页面错误相关开销信息 |
| source | source_function,source_file,source_line相关开销信息 |
| swaps | 交换次数相关开销信息 |
查出来之后,我们要怎么知道生命周期中的哪个步骤有猫病呢?主要观察如下四个:
show processlist 其实查询的是 information_schema.processlist 表。mysql> show processlist ;
+---------+-------------+---------------------+--------------------+---------+------+--------------+------------------------------------------------------------------------------------------------------+
| Id | User | Host | db | Command | Time | State | Info |
+---------+-------------+---------------------+--------------------+---------+------+--------------+------------------------------------------------------------------------------------------------------+
| 9801429 | lis | 10.41.7.10:57962 | lis | Query | 8 | Sending data | SELECT r.RgtantMobile, r.RgtantName, r.RgtNo, ag.SumGetMoney, ag.EnterAccDate, ag.BankAccNo, ( SELEC |
| 9802020 | ruihua | 10.41.5.6:37543 | sales_org | Sleep | 292 | | NULL |
| 9802070 | lis | 10.41.7.10:58998 | lis | Query | 8 | Sending data | select distinct d.contno,e.phone,d.appntidtype,d.appntidno,d.appntname,d.appntsex ,d.AppntBirthday,( |
| 9802084 | evoiceadmin | 10.41.8.8:41868 | evoicerh | Sleep | 57 | | NULL |
| 9802201 | root | 10.41.100.3:38976 | NULL | Query | 0 | init | show processlist |
+---------+-------------+---------------------+--------------------+---------+------+--------------+------------------------------------------------------------------------------------------------------+
148 rows in set (0.00 sec)
ID |
唯一连接标识 |
USER |
提交该语句的 MySQL 用户。 值为
system user 代表是服务器内部执行任务的无客户端线程,比如,一个 delayed-row 处理线程或者主从复制的一个 I/O or SQL 线程。对于 system user,在 Host column不指定任何Host值。值为unauthenticated user 代表已经建立了连接但是客户端用户还没有认证通过的线程。值为 event_scheduler 代表监控 scheduled events 的线程。 |
HOST |
提交语句的客户端的 host name |
DB |
线程的默认数据库,如果没有则是 NULL 。 |
COMMAND |
线程根据客户端行为正在执行的命令的类型,或是 Sleep如果连接空置 |
TIME |
线程处于当前状态的时间,以秒计 |
STATE |
描述线程正在做什么的 action。大多数状态都对应的很快的操作。如果一个线程在一个状态保持了很长时间,那么就是值得调查的问题了。 |
INFO |
线程正在执行的语句,如果没有执行则为 NULL 。语句可以是客户端发送到服务器的,也可以是某语句执行其他语句的内部语句。 |
四、慢日志
sql慢日志用于记录执行时间超过指定阈值的SQL,对于系统性能和故障排错非常有帮助,mysql默认是不开启的。
1、开启sql慢日志
(1)使用配置文件开始
/etc/my.cnf
[mysqld]
slow_query_log = ON
slow_query_log_file = /var/lib/mysql/instance-1-slow.log
long_query_time = 2
配置后,重启mysql。
(2)通过命令行开启
查询 SHOW VARIABLES LIKE 'long_query_time';
查询 SHOW VARIABLES LIKE 'slow_query_log';
设置 set global slow_query_log='ON';
设置 set global slow_query_log_file='/var/lib/mysql/instance-1-slow.log';
设置 set global long_query_time=2;
2、sql被记录到慢日志里,需要满足的条件
1. 管理类语句不会记录,除非开启了log_slow_admin_statements;
2. 执行时间需要超过long_query_time,或者对于未使用索引的SQL,需要开启log_queries_not_using_indexes,并且记录数量在log_throttle_queries_not_using_indexes之下;
3. SQL需要读取数据行数超过min_examined_row_limit;
4. 从库的复制语句默认不记录,除非binlog格式是statement且开启log_slow_slave_statements。
3、mysql.slow_log表