Linux内核中的预取算法
阅读数:182 评论数:0
跳转到新版页面分类
Linux
正文
1、存储设备的IO特性
(1)硬盘驱动器(HDD)
硬盘驱动器(HDD,Hard Disk Drive),简称硬盘或磁盘,是存储数字信息的首要介质。硬盘驱动器的主要部件是控制电路、缓存、伺服电机、磁头、盘片等。
磁盘具有大容量、随机读写能力以及高速顺序读写性能,这些主要特性都源自于IBM在1973年引入的温彻斯特(winchester)基本结构。其技术要点是:密封、固定并高速旋转的镀磁盘片,磁头悬浮在高速转动的盘片上方,沿盘片径向移动,而不与盘片直接接触。温彻斯特磁盘采用空气轴承(air bearing)技术,利用空气动力学原理使磁头在旋转的盘片上空悬浮,从而避免了低效的接触式访问方式。高速旋转和高密度磁记录的盘片造就了磁盘的大容量和快速顺序读写的优点,然而其机械臂的物理寻道方式极大地限制了其随机读写的性能。
磁盘的主要技术参数如下:
面密度(Areal Density)也称比特密度(Bit Density),用于表示盘片单位面积上能存储的数据量,单位通常是每平方英寸比特数(BPSI,Bits Pers square Inch)。
磁道密度(Track Density)度量磁盘上那些同心圆分布的磁道的排列紧凑程度:在单位径向距离中放置的磁道数。盘片的圆心部分是转轴,不能记录数据;最外圈也不能放置数据。如果一块磁盘在半径方向有1.2英寸的长度是用于存放数据的,在这一空间中有22000个磁道,则该磁盘的磁道密度是22000/1.2=18333磁道每英寸(TPI,Tracks Per Inch)。
线密度(Linear Density)或称记录密度(Record Density),它度量磁道上的比特密度,单位是比特每英寸每磁道(Bpl,BitsperInehpertrack)。一个盘片上每个磁道的长度都是不同的(因为它们是同心圆),记录密度也不一定相同。因而线密度/面密度一般指的是最大值或平均值。
每分钟转速(RPM,Revolutions per Minute)这一指标代表了硬盘主轴马达的转速,比如7200RPM就代表该硬盘中的主轴转速为每分钟7200转。
平均寻道时间(Average seek Time)指磁头从一个随机的当前位置移到指定的磁道上方所需要的平均时间,单位一般为毫秒(ms)。
(2)磁盘阵列(RAID)
RAID的功能可以由操作系统中的一个模块或是由专用的硬件控制器完成,前者称为软件RAID,后者称为硬件RAID。这两种RAID实现方式仅在造价、可管理性、速度与可靠性上存在区别,但是相对上层的操作系统和应用程序来说,RAID磁盘组看起来就像一个逻辑磁盘或存储单元。

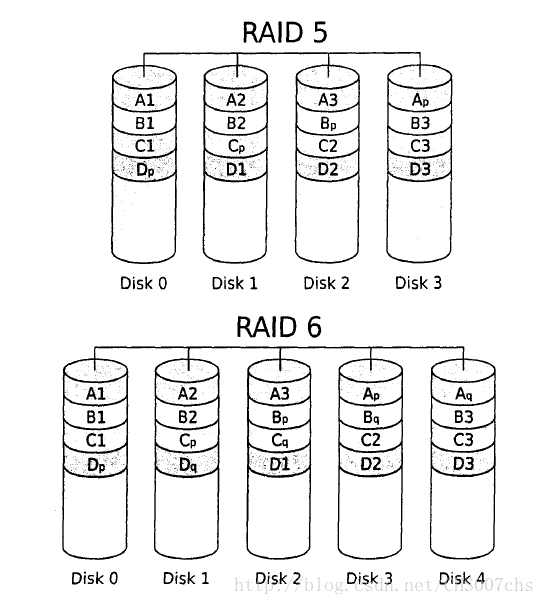
RAID一5的全称是分布式奇偶校验的条带集(striped set with distributed parity),它的数据在条带化后被分布存储于各个磁盘。与RAID一不同的是,RAID一5控制器为每N一1个数据块都生成对应的一个异或(XOR)校验块,并把这些校验块也分布到各个磁盘上。这样任何一个硬盘损坏,都可以根据其它硬盘上的校验位来重建损坏的数据。
RAID一6与RAID一5类似,只是它每N一2个数据块都生成2个校验块,因而能容许两块磁盘同时失效。
(3)固态硬盘(SSD)
固态硬盘(SSD,solid state Disk)是使用固态内存来持久保存数据的数字存储设备。SSD通常使用NAND闪存(flash memory)作为存储介质,但与同样基于闪存的存储卡不同的是,它把闪存模拟成一个硬盘,因而可以广泛兼容现有的软硬件应用。此外也有少数固态硬盘使用动态内存(DRAM)来存储数据,并依赖不间断供电和应急备份方案来保证数据的持久性。
SSD由控制单元和存储单元(flash芯片)两部分组成。存储单元负责存储数据,控制单元负责读取、写入数据。
2、IO性能优化方法
(1)避免IO 这是最有效的方法,避免磁盘访问就避免了IO操作的延迟和开销。缓存是避免访问存储设备的基本机制。
(2)顺序化 顺序访问可以使磁盘数据通道的有效利用率最大化。在有多个IO负载的情况下,做不到完全的顺序访问,也可以通过增加IO大小来尽量减少寻道次数。寻道操作越少,在数据定位上花费的时间就越少,磁盘能达到的吞吐量就越大。
(3)异步化 异步IO把所需数据提前加载到内存,以便向应用程序隐藏IO延迟。它可以使CPU和磁盘同时工作,从而提高计算机系统的利用率。
(4)并行化 把多个磁盘组织成一个以RAID为代表的阵列形式,并展开并行IO,是提升存储系练吞吐量的一个基本方法。进一步的方法是以集群的方式组织多个存储服务器进行并发数据服务。通过提升阵列或集群的规模,并进行并发FO,存储系统原则上可以满足任何1/0带宽的需求。
3、预取及其作用
预取算法预测即将访问的页面,并提前把它们批量读入内存缓存。预取有助于实现I/0的顺序化、异步化和并行化,从而改善I/O性能。
首先,异步预取(asynchronous read ahead)可以对上层应用程序隐藏磁盘IO延迟。其次,适当增大的预取粒度有助于提高磁盘的有效利用率和系统的IO吞吐量。
预取算法必须能够准确地识别应用程序的访问模式(access Pattem)和预测出即将被访问的数据页面,实现较高的模式识别率(Pattern recognition ratio)和预取命中率read ahead hit ratio)。对UNIx文件系统、数据库、科学计算等各种1/0负载类型的研究表明,顺序访问和随机访问是应用最普遍的两种访问模式。另外还可以见到交织的(interleaved)、条带的(stride)、反向的(reverse)等访问模式。传统的预取算法采用模式匹配的方法,监测应用程序对各个文件的读请求序列,维护一定的历史记录,并将其与上述模式逐一进行特征匹配。如果符合任何一种非随机的访问模式的特征,即可依此特征进行预测和预取。
预取(refetching)算法从慢速存储中加载数据到缓存
替换(rePlacement)算法从缓存中丢弃无用数据
写回(writeback)算法把脏数据从缓存中保存到慢速存储
Linux是一个类UNIX内核,它实现了包括POSIX、SYSV、BSD在内的一些UNIX系统调用接口。Linux的主要功能模块包括:进程调度,内存管理,文件系统,设备驱动,网络子系统
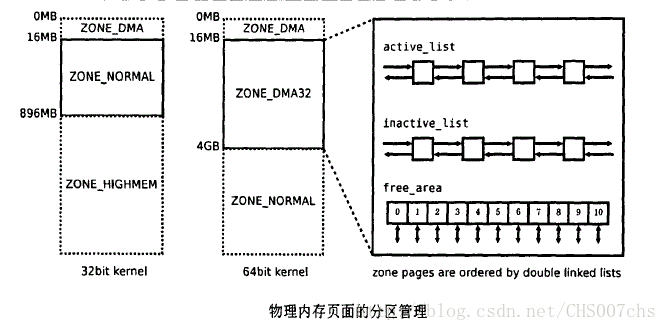
位于最低端的Zone_DMA内存区域是为ISA设备保留的,这些设备仅有16MB的DMA寻址能力。
ZONE_NORMAL中的页面具有1:1线性映射的物理地址和逻辑地址。运行在内核态的代码可以方便和高效地访问,内核中大部分数据结构的内存对象都使用这个区中的内存。
ZONE_HIGHMEM来自于32位内核的寻址能力限制。一个32位指针只能寻址4G字节。Linux默认按照1:3的比例对进程的地址空间进行划分,其中的IGB地址空间保留给内核使用,剩下的3GB是一个进程实际可用的虚拟地址空间。由于IGB可用地址空间的限制,不是所有的物理内存都可以被内核直接访问。称内核可以直接访问的为低端内存(low memory),不能直接访问的为高端内存(high memory)。Linux在一GB线性地址空间中1G出12sMB,主要用于映射访问高端内存。因而低端内存区(Zone_NORMAL)和高端内存区(ZONE_HIGHMEM)的分界线就在IGB一128MB=896MB处。数量众多的用户态进程申请使用的内存以及内核维护的文件缓存页面都优先从zoneHMEM中分配,其次才考虑ZONE_NORMAL。
ZONE一DMA32是为64位系统中的32.位设备准备的。在一个64位cPu上运行的64位Linux内核或进程本身没有高端内存的限制,但是系统中仍然可能存在可选的犯位设备。这些设备只能在4GB的地址空间中进行DMA操作,相应的内存就需要从ZONE_DMA32中分配。
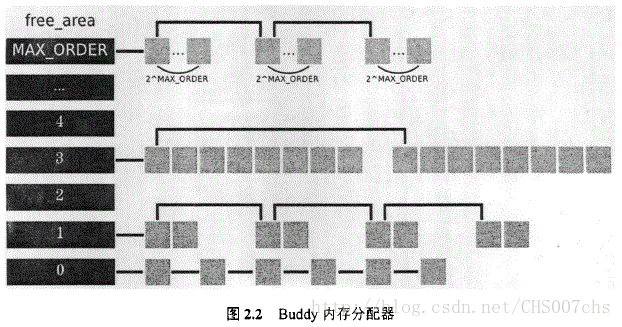
在每个zone中,Linux都维护一个free_area数据结构,并使用Buddy算法来管理和分配空闲的页面。在Buddy算法中,内存被划分为二的幂次方大小,并按此大小自然对齐的块组。Buddy算法另外还维护一个位图数组,用以快速地检索空闲页面在地址空间中的分布状况。
