Linux init_task描述符
阅读数:294 评论数:0
跳转到新版页面分类
Linux
正文
一、概述
内核中init_task变量是进程0使用的进程描述符,也是Linux系统中第一个进程描述符。
smp amp bmp
| 非对称多处理(Asymmetric multiprocessing) | 每个CPU内核运行一个独立的操作系统或同一操作系统的独立实例 |
| 对称多处理(Symmetric multiprocessing) | 一个操作系统的实例可以同时管理所有CPU内核,且应用并不绑定某一个内核 |
| 混合多处理(Bound multiprocessing) | 一个操作系统的实例可以同时管理所有CPU内核,但每个应用被锁定于某个指定的核心 |
task_struct
task_struct是Linux内核的一种数据结构,相关代码在include/linux/sched.h中, 每个进程都把它的信息放在task_struct这个数据结构体,在start_kernel中使用的init_task在init/init_task.c文件中初始化的.
task_struct包含如下内容:
(1)标示符
描述本进程的唯一标识符, 用来区别其他进程.
(2)状态
任务状态, 退出代码, 退出信号等.
(3)优先级
相对于其他进程的优先级
(4)程序计数器
程序中即将被执行的下一条指令的地址.
(5)内存指针
包括程序代码和进程相关数据的指针,还有和其他进程共享的内存块的指针.
(6)上下文数据
进程执行时处理器的数据.
(7)I/O状态信息
包括显示的IO请求,分配给进程的IO设备的被使用的文件列表
(8)记账信息
可能包括处理器时间总和, 使用的时钟数总和, 时间限制,记账号等.
二、进一步分析
1. 为什么需内核栈
内核态的进程访问处于内核数据段的栈, 这个栈不同于用户态的进程所用的栈。当进程从用户空间进入内核空间时特权级发生变化,需要切换堆栈,那么内核空间中使用的就是这个内核栈。因为内核控制路径使用很少的栈空间,所以只需几KB的内核态栈。
Linux内核另外为中断提供了单独的硬中断和软中断栈。
2、为什么需要thread_info
内核还需要存储每个进程的PCB信息,linux内核是支持不同体系的,但是不同的体系结构可能进程需要存储的信息不尽相同,这就需要我们实现一种通用的方式,我们将体系结构相关的部分和无关的部分进行分离。
用一种通用的方式描述进程,这就是struct task_struct,而thread_info就保存了特定体系结构的汇编代码段需要访问的那部分进程的数据,我们在thread_info中嵌入指向task_struct的指针,则我们可以很方便的通过thread_info查找task_struct。
thread_info定义在thread_info.h中
| 架构 | 定义链接 |
| x86 | arch/x86/include/asm/thread_info.h |
| arm | arch/arm/include/asm/thread_info.h |
| arm64 | arch/arm64/include/asm/thread_info.h |
3、进程相关数据结构
(1)CURRENT宏
task_struct在linux/sched.h文件里定义,在使用current宏的时候一定要引这个头文件,在linux内核编程中常用的current宏可以非常简单地获取到指向task_struct的指针,这个宏和体系统结构有关,大多数情况下,我们都是x86体系结构的,所以在arch/x86目录下,其他体结构类推。
目前主流的体系结构有x86、ARM、MIPS架构,在继续学习之前,我们先来简单了解一下什么是体系结构。
目前主流的体系结构有x86、arm、mips架构 ,我们先来简单了解一下什么是体系结构:“体系结构”用来描述一个抽象的机器,而不是一个具体的机器实现,一般而言,一个CPU的体系结构有一个指令集加上一些寄存器而组成。
x86、mips、arm三种cpu的体系结构和特点:
- X86
X86采用了CISC指令集。在CISC指令集的各种指令中,大约有20%的指令会被反复使用,占整个程序代码的80%。而余下的80%的指令却不经常使用,在程序设计中只占20%。
1.1 总线接口部件BIU
总线接口部件由以下几部分组成
1) 4个16位段寄存器(DS、ES、SS、CS)
2) 一个16位指令指针寄存器(IP)
3) 20位物理地址加法器
4) 6字节指令队列(8088为4字节)
5) 总线控制电路组成,负责与存储器及I/O端口的数据传送
1.2 执行部件EU
执行部件由以下几部分组成,其任务就是从指令队列流中取出指令,然后分析和执行指令,还负责计算操作数的16位偏移地址
1) ALU
2) 寄存器阵列(AX、BX、CX、DX、SI、DI、BP、SP)
3) 标志寄存器(PSW)等几个部分组成
1.3 寄存器的结构
1) 数据寄存器AX、BX、CX、DX均为16位的寄存器,它们中的每一个又可分为高字节H和低字节L。即AH、BH、CH、DH及AL、BL、CL、DL可作为单独的8位寄存器使用。不论16位寄存器还是8位寄存器,它们均可寄存操作数及
运算的中间结果。有少数指令指定某个寄存器专用,例如,串操作指令指定CX专门用作记录串中元素个数的计数器。
2) 段寄存器组:CS、DS、SS、ES。8086/8088的20位物理地址在CPU内部要由两部分相加形成的
2.1) 指明其偏移地址
SP、BP、SI、DI标识20位物理地址的低16位,用于指明其偏移地址
2.2) 指明20位物理地址的高16位,故称作段寄存器,4个存储器使用专一,不能互换
2.2.1) CS: CS识别当前代码段
2.2.2) DS: DS识别当前数据段
2.2.3) SS: SS识别当前堆栈段
2.2.4) ES: ES识别当前附加段
一般情况下,DS和ES都须用户在程序中设置初值
3) 控制寄存器组
3.1) IP
指令指针IP用以指明当前要执行指令的偏移地址(段地址由CS提供)
3.2) FLAG
标志寄存器FLAG有16位,用了其中的九位,分两组:
3.2.1) 状态标志: 用以记录状态信息,由6位组成,包括CF、AF、OF、SF、PF和ZF,它反映前一次涉及ALU操作的结果,对用户它"只读不写"
3.2.2) 控制标志: 用以记录控制信息由3位组成,包括方向标志DF,中断允许标志IF及陷阱标志TF,中断允许标志IF及陷阱标志TF,可通过指令设置
2. MIPS:
1) 所有指令都是32位编码;
2) 有些指令有26位供目标地址编码;有些则只有16位。因此要想加载任何一个32位值,就得用两个加载指令。16位的目标地址意味着,指令的跳转或子函数的位置必须在64K以内(上下32K)
3) 所有的动作原理上要求必须在1个时钟周期内完成,一个动作一个阶段
4) 有32个通用寄存器,每个寄存器32位(对32位机)或64位(对64位机)
5) 对于MIPS体系结构来说,本身没有任何帮助运算判断的标志寄存器,要实现相应的功能时,是通过测试两个寄存器是否相等来完成
6) 所有的运算都是基于32位的,没有对字节和对半字的运算(MIPS里,字定义为32位,半字定义为16位)
7) 没有单独的栈指令,所有对栈的操作都是统一的内存访问方式。因为push和pop指令实际上是一个复合操作,包含对内存的写入和对栈指针的移动;
8) 由于MIPS固定指令长度,所以造成其编译后的二进制文件和内存占用空间比x86的要大,(x86平均指令长度只有3个字节多一点,而MIPS是4个字节)
9) 寻址方式:只有一种内存寻址方式。就是基地址加一个16位的地址偏移
10) 内存中的数据访问必须严格对齐(至少4字节对齐)
11) 跳转指令只有26位目标地址,再加上2位的对齐位,可寻址28位的空间,即256M
12) 条件分支指令只有16位跳转地址,加上2位的对齐位,共18位寻址空间,即256K
13) MIPS默认不把子函数的返回地址(就是调用函数的受害指令地址)存放到栈中,而是存放到$31寄存器中;这对那些叶子函数有利。如果遇到嵌套的函数的话,有另外的机制处理;
14) 高度的流水线: *MIPS指令的五级流水线:(每条指令都包含五个执行阶段)
14.1) 第一阶段:从指令缓冲区中取指令。占一个时钟周期
14.2) 第二阶段:从指令中的源寄存器域(可能有两个)的值(为一个数字,指定$0~$31中的某一个)所代表的寄存器中读出数据。占半个时钟周期
14.3) 第三阶段:在一个时钟周期内做一次算术或逻辑运算。占一个时钟周期
14.4) 第四阶段:指令从数据缓冲中读取内存变量的阶段。从平均来讲,大约有3/4的指令在这个阶段没做什么事情,但它是指令有序性的保证。占一个时钟周期
14.5) 第五阶段:存储计算结果到缓冲或内存的阶段。占半个时钟周期
所以一条指令要占用四个时钟周期
3. ARM
ARM处理器是一个32位元精简指令集(RISC)处理器架构,其广泛地使用在许多嵌入式系统设计
1) RISC(Reduced Instruction Set Computer,精简指令集计算机)
RISC体系结构应具有如下特点:
1.1) 采用固定长度的指令格式,指令归整、简单、基本寻址方式有2~3种
1.2) 使用单周期指令,便于流水线操作执行。
1.3) 大量使用寄存器,数据处理指令只对寄存器进行操作,只有加载/ 存储指令可以访问存储器,以提高指令的执行效率
2) ARM体系结构还采用了一些特别的技术,在保证高性能的前提下尽量缩小芯片的面积,并降低功耗
2.1) 所有的指令都可根据前面的执行结果决定是否被执行,从而提高指令的执行效率
2.2) 可用加载/存储指令批量传输数据,以提高数据的传输效率。
3) 寄存器结构
ARM处理器共有37个寄存器,被分为若干个组(BANK),这些寄存器包括
3.1) 31个通用寄存器,包括程序计数器(PC指针),均为32位的寄存器
3.2) 6个状态寄存器,用以标识CPU的工作状态及程序的运行状态,均为32位
4) 指令结构
ARM微处理器的在较新的体系结构中支持两种指令集:ARM指令集和Thumb指令集。其中,ARM指令为32位的长度,Thumb指令为16位长度。Thumb指令集为ARM指令集的功能子集,但与等价的ARM代码相比较,可节省30%~40%以上的
存储空间,同时具备32位代码的所有优点。
set_task_stack_end_magic
进入start_kernel, set_task_stack_end_magic(&init_task)函数设置整个系统的第一个进程。其中,init_task这个变量是在init/init_task.c中。回到start_kernel函数中,set_task_stack_end_magic函数的原型是kernel/Fork.c中
void set_task_stack_end_magic(struct task_struct *tsk){unsigned long *stackend;stackend = end_of_stack(tsk);*stackend = STACK_END_MAGIC; /* for overflow detection */}
这个end_of_stack在include/linux/sched.h中,它的意思是获取栈边界地址,然后把栈底内容设置为STACK_END_MAGIC,这个作为栈溢出的标记。
Linux的list_head
首先找到list_head结构体定义,/include/linux/types.h如下:
struct list_head {
struct list_head *next, *prev;
};
接下来我们看/include/linux/list.h
#define LIST_HEAD_INIT(name) { &(name), &(name) }
#define LIST_HEAD(name) \
struct list_head name = LIST_HEAD_INIT(name)
static inline void INIT_LIST_HEAD(struct list_head *list)
{
WRITE_ONCE(list->next, list);
list->prev = list;
}
可以通过LIST_HEAD(mylist)进行初始化一个链表,mylist的prev和next指针都指向自己。
RCU机制
Read-Copy Update是数据同步的一种方式,RCU主要针对的数据对象是链表,目的是提高遍历读取数据的效率,为了达到目的使用RCU机制读取数据的时候不对链表进行耗时的加锁操作。这样在同一时间可以有多个线程同时读取该链表,并且允许一个线程对链表进行修改(修改的时候,需要加锁)。RCU适用于需要频繁的读取数据,而相应修改数据并不多的情景,例如在文件系统中,经常城要查找定位目录,而对目录的修改相对来说并不多,这就是RCU发挥作用的最佳场景。
在Linux源码的/Documentation/RCU/目录下可以找到RCU相关的文档。
RCU的原理可以简述:RCU记录了所有对共享数据的使用者,当内核线程需要write某个数据时,先创建一个副本,在副本中修改。当所有读线程都离开临界区后,新的数据才被更新。
1、宽限期(Grace period)
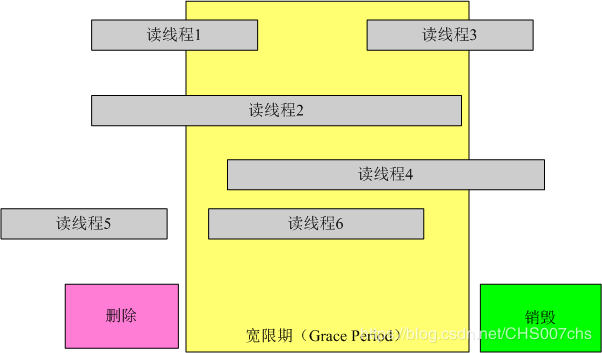
图中每行代表一个线程,最下面的一行是删除线程,当它执行删除操作后,线程进入了宽限期。宽限期的意义是,在一个删除动作发生后,它必须等待所有宽限期开始前已经开如的读线程结束,才可以进行销毁操作。这样做的原因是这些线程有可能读到了要删除的元素。图中的宽限期必须等待1和2结束,而读线程5在宽限期开始已经结束,不需要考虑,而3、4、6也不城要考虑。
2、数据读取的完整性
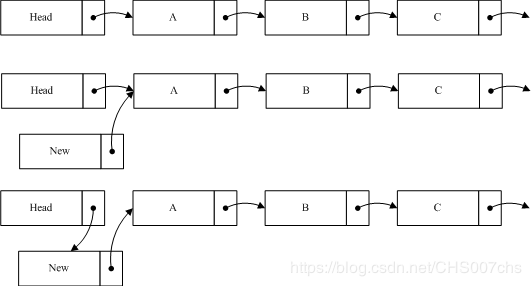
如图我们在原list中加入一个节点new到A之前,所要做的第一步是将new的指针指和A节点,第二步才是将Head指针指向new。这样做的目的是当插入操作完成第一步的时候,对于链表的读取并不产生影响,而执行完第二步时候,读线程如果读到new,由于new指针指向的是null,这样将导制读线程无法读取到A、B等后续节点。从以上过程中,可以看出RCU并不保证读线程读取到new节点。
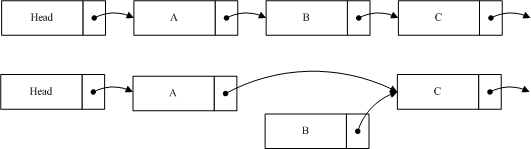
如图我们希望删除B,这时候要做的就是将A的指针指向C,保持B的指针,然后删除程序将进入宽限期检测,由于B的内容并没有变更,读到B的线程仍然可以继续读取B的后续节点。B不能销毁,它必须等待宽限期结束后,才能进行相应销毁操作。由于A的节点已经指向了C,当宽限期之后所有后续读操作通过A找到的是C,而B已经隐藏了,后续的读线程都不会读到它。这样就确保宽限期过后,删除B并不对系统造成影响。
cred管理
一个对象操作另一个对象时通常做安全性检查。如一个进程操作一个文件,要检查进程是否有权操作该文件。credential机制的引入,正是对象间访问所需权限的抽象,主体提供自己权限的证书,客记提供访问自己所需权限的证书,根据主客户体提供的证书及操作做安全性检查。
ABI
1、Application Binary Interface,应用程序二进制接口。即然是接口,那就是某两种东西的沟通桥梁,此处有这种情况:
(1)应用程序 -- 操作系统
(2)应用程序 -- (应用程序所用到的)库
(3)应用程序各个组件之间
类似于API的作用是使得程序的代码的兼容,ABI的目的是使得程序的二进制(级别)的兼容。
2、什么是OABI和EABI
OABI中的O表示“Old”,就是旧的ABI,EABI的E表示Embedded,也叫做GNU EABI,OABI和EABI都专门针对ARM的CPU来说的。
LSM
LSM是Linux Security Module的简称,即Linux安全模块,是一种轻量级通用访问控制框架。
LSM的设计思想:在最少改变内核代码的情况下,提供一个能够成实现强制访问控制模块需要结构都只者接口。对于使用的人来说尽量少引入麻烦,对使用的人来说要带来效率。