fastspeech2
阅读数:177 评论数:0
跳转到新版页面分类
AI
正文
一、概述
1、简介
非自回归tts模型可以比质量相当的自回归模型更快的合成语音,以前的神经tts模型首先从文本自加归生成mel谱图,然后使用单独训练的声码器从生成的mel谱图合成语音。它们通常存在推理速度慢和健壮性的问题。非回归tts模型旨在解决这些问题,以更快的速度生成mel谱图并避免鲁棒性问题,同时实现与以前的自回归模型相当的语音质量。
在这些非回归的tts模型中,fastspeech是最成功的模型之一。
FastSpeech2的训练速度比FastSpeech提高了3倍,推理速度更快。
2、tts的常见问题
tts是一个典型的一对多映射问题,因为多种可能的语音序列可以对应一个文本序列,这是由于语音的变化 。
二、模型概述
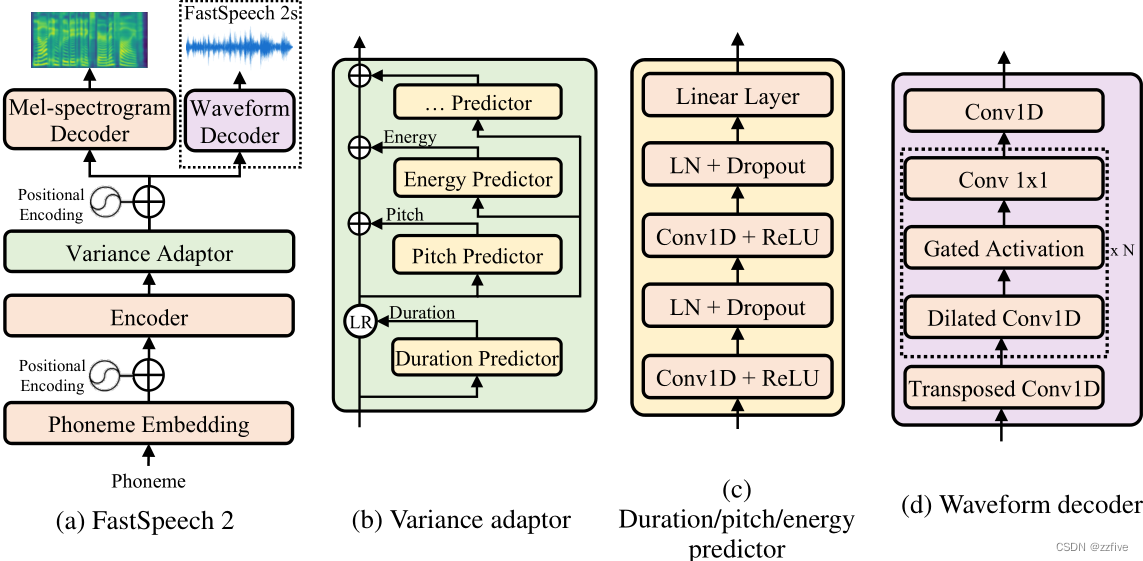
FastSpeech2的整体模型架构如图1(a):
(1)编码器将音素(phoneme)嵌入序列转换为音素隐藏序列。
(2)方差(variance)适配器将时长、基音、能量等不同的方差信息加入到隐藏序列中
(3)然后由mel频谱(spectrogram)译码器将调整后的隐藏序列并行转换为mel-频谱序列。
三、方差适配器(variance adaptor)
方差适配器的目的是在音素隐藏序列中加入方差信息(如持续时间、音高、能量等),为TTS中的一对多映射问题提供足够的信息来预测变异语音。
1、音素持续时间(duration)
表示语音声音发声的时长。
2、音调(pitch)
这是传达情感的关键特征,对语音韵律有很大影响。
3、能量(energy)
表示mel谱图的帧级幅度,直接影响语音的音量和韵律。
如图(c),持续时间、音调和能量预测器的模型结构相似(但模型参数不同).
4、持续时间预测器
持续时间预测器以音素隐藏序列为输入,预测每个音素的持续时间,即该音素对应多少mel帧,并将其转换为对数域,便于预测。以提取的持续时间为训练目标,利用均方误差损失优化持续时间预测器。使用MFA(Montreal forced alignment)工具来提取音素持续时间,以提高对齐精度,从而减少模型输入和输出之间的信息差距。
5、音调预测器
为了更好的预测基音轮廓的变化,使用连续小波变换(cwt)将连续的基音序列分解为基音谱图,并以音高谱图作为训练目标,用MSE损失优化音高预测器。
6、能量预测器
将每个短时傅里叶变换 (STFT) 帧的幅度的 L2 范数计算为能量。然后将每帧的能量统一量化为 256 个可能的值,将其编码为能量嵌入 e 并将其添加到扩展的隐藏序列中,类似于音高。使用能量预测器来预测能量的原始值而不是量化值,并使用 MSE 损失优化能量预测器。
四、fastspeech 2s
它直接从文本生成波形,而不需要级联mel频谱图生成(声学模型)和波形生成(声码器)。