数据库如何处理大数据量
阅读数:86 评论数:0
跳转到新版页面分类
数据库
正文
一、概述
常见操作:分区、分库分表、主从架构(读写分离)。
1、分区
隔离数据访问,就是把一张表的数据分成N个区块,在逻辑上看最终只是一张表,但底层是由N个物理区块组成的。
2、分库分表
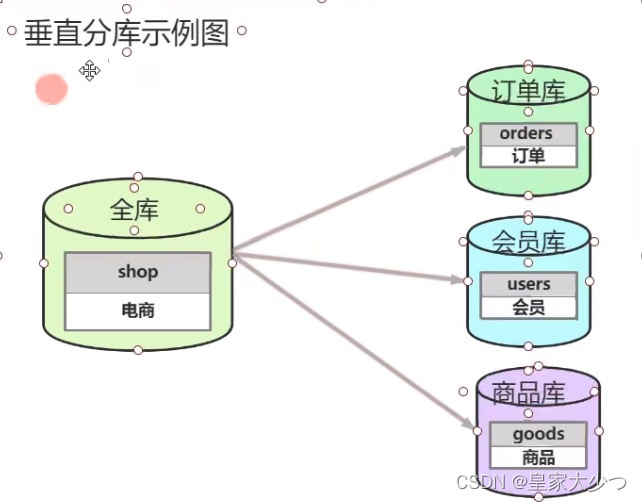
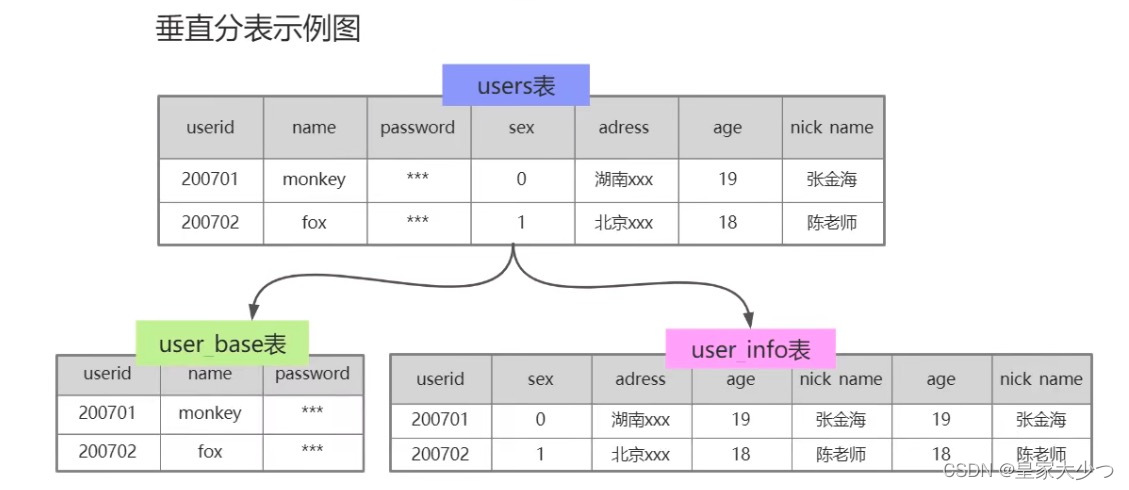
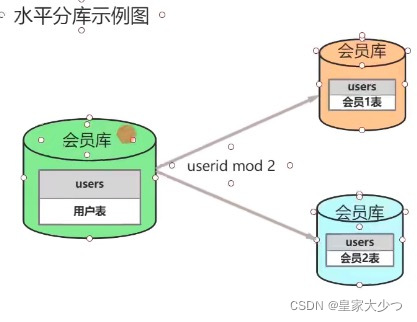
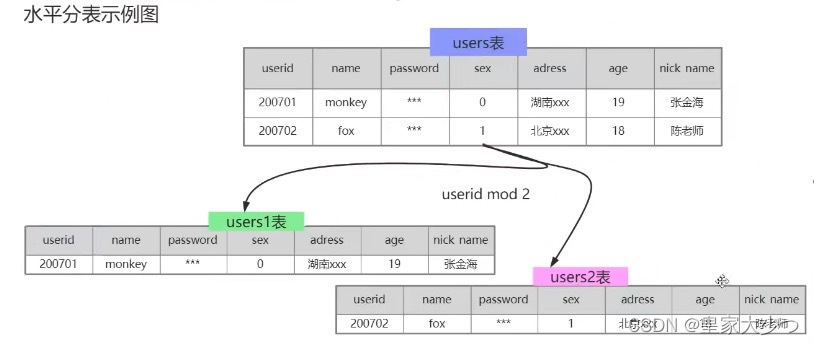
横向分库分表,各个库和表的结构一模一样。垂直分库分表,各个库和表的结构不一样。
分表就是把一张数据量很大的表按一定的规则分解成N个实体表,系统读写时需要根据定义好的规则 得到对应的字段,然后操作它,一般单表数据量大于500W或者并发大于1200时考虑分表。
分库,当一个库中的表越来越多时,一般大于200时,考虑分库。
(1)分库分表带来的问题
分布式事务、跨库join查询 、分布式分局唯一id
(2)分库分表的开源框架
| jdbc直连层 | shardingsphere、tddl |
| proxy代理层 | mycat、mysql-proxy |
3、读写分离
主机负责写、从机负责读。
二、mysql的分区、分库分表、读写分离
1、分区
mysql数据库中的数据是以文件的形势存在磁盘上的,默认放在/mysql/data下面(可以通过my.cnf中的datadir来查看),一张表主要对应着三个文件,一个是frm存放表结构的,一个是myd存放表数据的,一个是myi存表索引的。如果一张表的数据量太大的话,那么myd,myi就会变的很大,查找数据就会变的很慢,这个时候我们可以利用mysql的分区功能
(1)查看是分否支持分区
mysql> show variables like "%part%";
+-------------------+-------+
| Variable_name | Value |
+-------------------+-------+
| have_partitioning | YES |
+-------------------+-------+
row in set (0.00 sec)(2)range分区
这种模式允许将数据划分不同范围。例如可以将一个表通过年份划分成若干个分区
create table t_range(
id int(11),
money int(11) unsigned not null,
date datetime
)partition by range(year(date))(
partition p2007 values less than (2008),
partition p2008 values less than (2009),
partition p2009 values less than (2010)
partition p2010 values less than maxvalue #MAXVALUE 表示最大的可能的整数值
);RANGE分区在如下场合特别有用:
| 当需要删除一个分区上的“旧的”数据时,只删除分区即可。如果你使用上面最近的那个例子给出的分区方案,你只需简单地使用”ALTER TABLE employees DROP PARTITION p0;” 来删除所有在1991年前就已经停止工作的雇员相对应的所有行。对于有大量行的表,这比运行一个如”DELETE FROM employees WHERE YEAR (separated) <= 1990;” |
| 想要使用一个包含有日期或时间值,或包含有从一些其他级数开始增长的值的列。 |
| 经常运行直接依赖于用于分割表的列的查询。 例如,当执行一个如”SELECT COUNT(*) FROM employees WHERE YEAR(separated) = 2000 GROUP BY store_id;”这样的查询时, |
(3)list分区
这种模式允许系统通过预定义的列表的值来对数据进行分割。
create table t_list(
a int(11),
b int(11)
)(partition by list (b)
partition p0 values in (1,3,5,7,9),
partition p1 values in (2,4,6,8,0)
);(4)hash分区
这中模式允许通过对表的一个或多个列的Hash Key进行计算,最后通过这个Hash码不同数值对应的数据区域进行分区。例如可以建立一个对表主键进行分区的表。
CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT,
store_id INT
)
PARTITION BY HASH(store_id)
PARTITIONS 4;(5)key分区
上面Hash模式的一种延伸,这里的Hash Key是MySQL系统产生的。
CREATE TABLE tk (
col1 INT NOT NULL,
col2 CHAR(5),
col3 DATE
)
PARTITION BY LINEAR KEY (col1)
PARTITIONS 3;(6)子分区
子分区是分区表中每个分区的再次分割,子分区既可以使用HASH希分区,也可以使用KEY分区。这 也被称为复合分区(composite partitioning)。
| 如果一个分区中创建了子分区,其他分区也要有子分区 |
| 如果创建了子分区,每个分区中的子分区数必有相同 |
mysql> CREATE TABLE IF NOT EXISTS `sub_part` (
-> `news_id` int(11) NOT NULL COMMENT '新闻ID',
-> `content` varchar(1000) NOT NULL DEFAULT '' COMMENT '新闻内容',
-> `u_id` int(11) NOT NULL DEFAULT 0s COMMENT '来源IP',
-> `create_time` DATE NOT NULL DEFAULT '0000-00-00 00:00:00' COMMENT '时间'
-> ) ENGINE=INNODB DEFAULT CHARSET=utf8
-> PARTITION BY RANGE(YEAR(create_time))
-> SUBPARTITION BY HASH(TO_DAYS(create_time))(
-> PARTITION p0 VALUES LESS THAN (1990)(SUBPARTITION s0,SUBPARTITION s1,SUBPARTITION s2),
-> PARTITION p1 VALUES LESS THAN (2000)(SUBPARTITION s3,SUBPARTITION s4,SUBPARTITION good),
-> PARTITION p2 VALUES LESS THAN MAXVALUE(SUBPARTITION tank0,SUBPARTITION tank1,SUBPARTITION tank3)
-> );
Query OK, 0 rows affected (0.07 sec)(7)分区的管理
alter table user add partition(partition p4 values less than MAXVALUE);#新增range分区
alter table list_part add partition(partition p4 values in(25,26,27)) #新增list分区
alter table hash_part add partition partitions 4; # hash重新分区
alter table key_part add partition partitions 4; #key 重新分区
//子分区添加新分区,虽然我没有指定子分区,但是系统会给子分区命名的
alter table sub1_part add partition(partition p3 values less than MAXVALUE);
//range重新分区
ALTER TABLE user REORGANIZE PARTITION p0,p1,p2,p3,p4 INTO (PARTITION p0 VALUES LESS THAN MAXVALUE);
//list重新分区
ALTER TABLE list_part REORGANIZE PARTITION p0,p1,p2,p3,p4 INTO (PARTITION p0 VALUES in (1,2,3,4,5));
#hash和key分区不能用REORGANIZE,官方网站说的很清楚
#删除分区
alter table user drop partion p42、分表
利用mysql cluster ,mysql proxy,mysql replication,drdb等等