java8 stream流
阅读数:77 评论数:0
跳转到新版页面分类
python/Java
正文
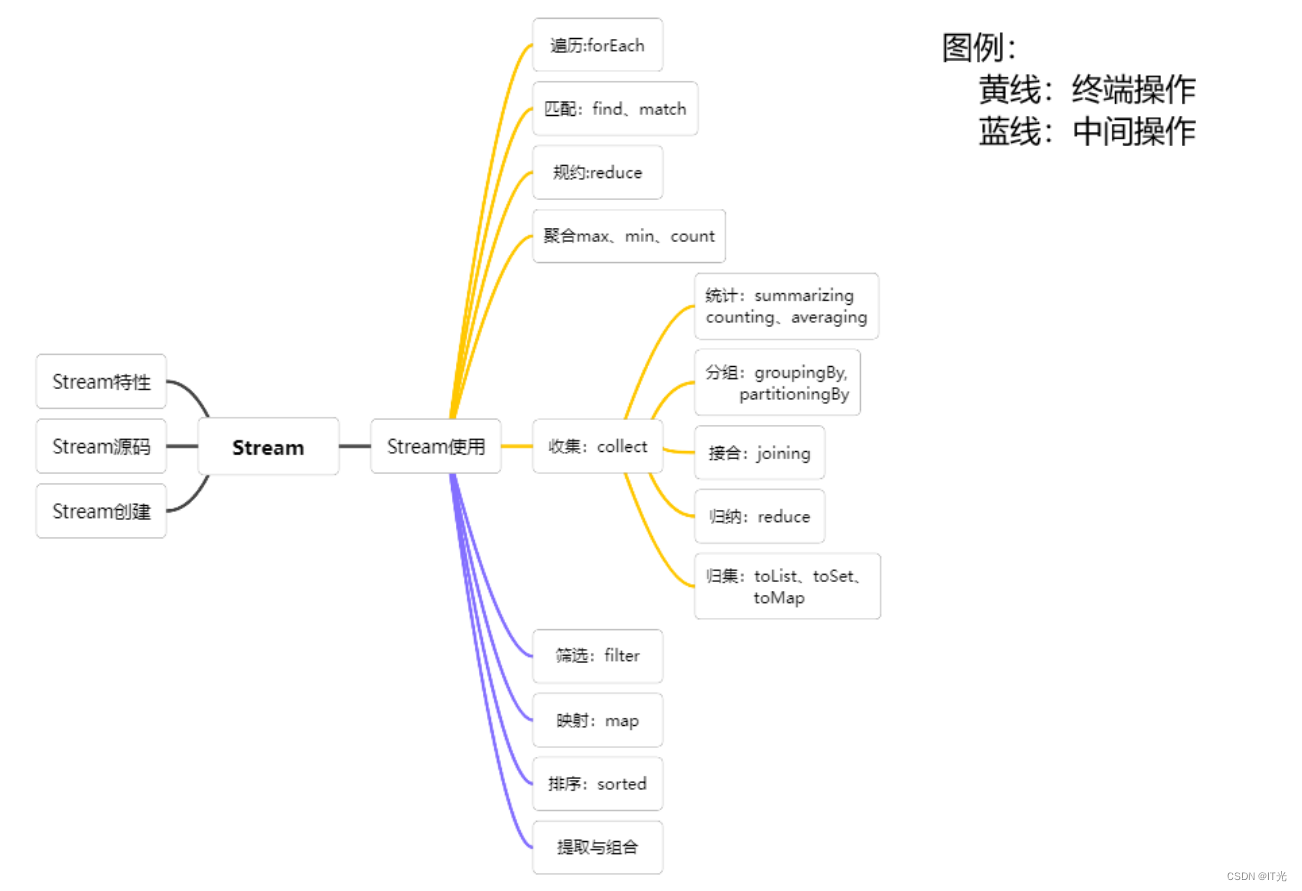
一、概述
如果没有终端操作,中间操作是不会得到执行的(惰性求值)。
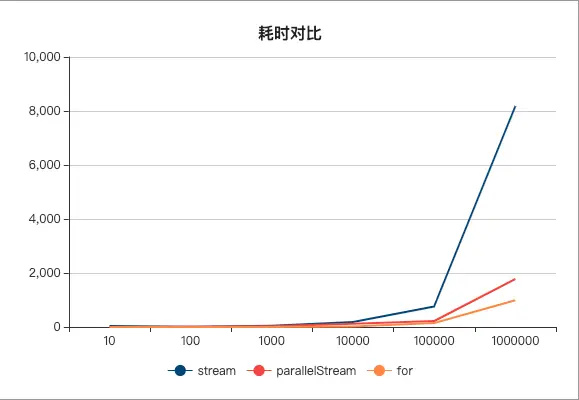
stream的使用可以将代码中大量的for循环变为简单的链式函数操作,但是需要注意性能,在数据量小的情况下二都相差不多,但是在数据量很大时,for的性能还是优越于stream。
二、Stream的生成
支持串行或并行的方式,在Collection接口中,分别用两种方式来生成:
1、串行流:stream()
2、并行流:parallelStream()
public class Test02 {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("张三");
list.add("李四");
list.add("王五");
//第一种:通过集合对象调用stream
Stream<String> stream = list.stream();//获取Stream流
stream.forEach(System.out::println); //打印
//第二种:通过Arrays获取stream流对象
String[] arr = {};
Stream<String> stream1 = Arrays.stream(arr);
//第三种:通过Stream流里面of方法
Stream<Integer> integerStream = Stream.of(1, 2, 3, 4);
//上面三种流都是串行流。 并行流:
Stream<String> stringStream = list.parallelStream();
stringStream.forEach(System.out::println);
}
}三、Stream常用接口方法
用于遍历流中的每个元素。终结方法。
void forEach(Consumer<? super T> action);
// 遍历Map的键:
Map<String, Integer> map = new HashMap<>();
map.put("A", 1);
map.put("B", 2);
map.put("C", 3);
map.keySet().forEach(key -> System.out.println(key));
//遍历Map的值
Map<String, Integer> map = new HashMap<>();
map.put("A", 1);
map.put("B", 2);
map.put("C", 3);
map.values().forEach(value -> System.out.println(value));
//遍历Map的键值对:
Map<String, Integer> map = new HashMap<>();
map.put("A", 1);
map.put("B", 2);
map.put("C", 3);
map.forEach((key, value) -> System.out.println(key + " : " + value));
Map<String, Integer> map = new HashMap<>();
map.put("A", 1);
map.put("B", 2);
map.put("C", 3);
map.entrySet().stream().forEach(entry ->
System.out.println(entry.getKey() + " : " + entry.getValue()));
Stream map(Function<? super T, ? extends R> mapper)
IntStream mapToInt(ToIntFunction<? super T> mapper)
DoubleStream mapToDouble(ToDoubleFunction<? super T> mapper)Stream API中的一个中间操作,它允许我们将每个元素映射到另一个元素,从而创建一个新的Stream。
List words = Arrays.asList("Hello", "World");
List wordLengths = words.stream()
.map(String::length)
.collect(Collectors.toList());在这个例子中,map()方法将每个单词映射到它的长度,并将结果收集到一个List中。注意到String::length语法,这是一个方法引用,用来指定将String对象映射到它的长度的Lambda表达式。
(1)类型转换
通过map()方法,我们可以将Stream的元素类型转换为另一种类型,如下所示:
List strList = Arrays.asList("123", "345", "678");
List intList = strList.stream()
.map(Integer::valueOf)
.collect(Collectors.toList());(2)与过滤器的组合
Stream Map和Stream Filter是两个常用的中间操作,它们可以组合使用来对Stream进行处理。Stream Map可以先将元素映射到另一种类型,然后使用Stream Filter过滤掉不需要的元素。
List words = Arrays.asList("Java", "Stream", "API", "Map", "Filter");
List result = words.stream()
.map(String::toUpperCase)
.filter(s -> s.startsWith("S"))
.collect(Collectors.toList());(3)多级映射
Stream Map还支持多级映射,其中一个map()方法会返回另一个Stream,可以对返回的Stream进行另一次映射
List> numbers = Arrays.asList(Arrays.asList(1, 2), Arrays.asList(3, 4, 5), Arrays.asList(6, 7, 8, 9));
List result = numbers.stream()
.flatMap(Collection::stream)
.collect(Collectors.toList());在这个例子中,flatMap()方法将多个List合并为一个Stream,并将每个元素映射为它的值。最后结果存储到一个List中。
Stream filter(Predicate<? super T> predicate)用于通过设置的条件过滤出元素。Stream中符合条件的,即Lambda表达式值为true的元素被保留下来。该Lambda表达式的函数接口正是Predicate
List<String>strings = Arrays.asList("abc", "", "bc", "efg", "abcd","", "jkl");
// 获取空字符串的数量
long count = strings.stream().filter(string -> string.isEmpty()).count();
(1)findAny+orElse
public static void main(String[] args) {
List<User> userList = Arrays.asList(
new User("张三", 30),
new User("李四", 20),
new User("Enoch", 40)
);
User result1 = userList.stream() // 转化为流
.filter(x -> "Enoch".equals(x.getName())) // 只过滤出"Enoch"
.findAny() // 如果找到了就返回
.orElse(null); // 如果找不到就返回null
System.out.println(result1);
User result2 = userList.stream()
.filter(x -> "Enoch".equals(x.getName()))
.findAny()
.orElse(null);
System.out.println(result2);
}
Stream limit(long maxSize)限制流中元素的数量,并返回一个新的流。它接受一个long类型的参数,表示要保留的元素数量。
Random random = new Random();
random.ints().limit(10).forEach(System.out::println);
Stream sorted()
Stream sorted(Comparator<? super T> comparator)用于对流进行排序。默认使用自然序排序, 其中的元素必须实现Comparable 接口。
#自然序排序一个list
list.stream().sorted()
#自然序逆序元素,使用Comparator 提供的reverseOrder() 方法
list.stream().sorted(Comparator.reverseOrder())
# 使用Comparator 来排序一个list
list.stream().sorted(Comparator.comparing(Student::getAge))
# 颠倒使用Comparator 来排序一个list的顺序,使用Comparator 提供的reverseOrder() 方法
list.stream().sorted(Comparator.comparing(Student::getAge).reversed())
(1)自定义排序
List<UcasFileInfo> filter = ucasFileInfos.stream().filter(item->{
return item.getTextNums() != null && StringUtils.isNoneEmpty(item.getArchFileNo());
}).sorted(new Comparator<UcasFileInfo>(){
@Override
public int compare(UcasFileInfo o1, UcasFileInfo o2) {
if(Integer.valueOf(o1.getArchFileNo()) > Integer.valueOf(o2.getArchFileNo())){
return 1;
} else if(Integer.valueOf(o1.getArchFileNo()) == Integer.valueOf(o2.getArchFileNo())){
return 0;
} else {
return -1;
}
}
}).collect(Collectors.toList());(2)多字段排序
List<userInfo> userList3 = userList.stream()
.sorted(Comparator.comparing(userInfo::getAge)
.thenComparing(userInfo::getMoney,Comparator.reverseOrder())).collect(Collectors.toList());
long count()
Optional reduce(BinaryOperator accumulator)// 计数求及格的学生人数
long count = students.stream().filter(student -> student.getScore() > 60).count();
// 求分数总和
Integer sum = students.stream().map(Student::getScore).reduce(Integer::sum).orElse(-1);
Integer sum2 = students.stream().mapToInt(Student::getScore).sum();
// 分数的平均值
double average = students.stream().mapToDouble(Student::getScore).average().orElse(0D);
System.out.println(count + "-" + sum + "-" + average);
Optional max(Comparator<? super T> comparator)
Optional min(Comparator<? super T> comparator)// 分数的最大值 最小值
Student max = students.stream().max(Comparator.comparing(Student::getScore)).orElse(null);
Student min = students.stream().min(Comparator.comparing(Student::getScore)).orElse(null);
// 也可以通过如下写法获取最大值,这种写法只能获取到值,没法关联用户,跟上面的写法各有用途
int max2 = students.stream().mapToInt(Student::getScore).max().orElse(0);
int min2 = students.stream().mapToInt(Student::getScore).min().orElse(0);
System.out.println(max);
System.out.println(min);
<R, A> R collect(Collector<? super T, A, R> collector)
<R> R collect(Supplier<R> supplier, BiConsumer<R, ? super T> accumulator, BiConsumer<R, R> combiner)
| supplier | 无参构造器,提供一个无参初始化容器的方法 |
| accumulator | 累加器,提供容器增加元素的方法 |
| combiner | 合并函数,提供一个容器合并的方法(因为流内部会使用并行的方式,多个线程会创建多个容器添加元素,以提高执行效率) |
// 流转集合
List<Student> studentList = students.stream().collect(Collectors.toList());
// 使用该方法,可以把流转map或任意集合对象
HashMap<String, Student> map = students.stream()
.collect(HashMap::new,
(hashMap, student) -> hashMap.put(student.getName(), student),
HashMap::putAll);
Optional findFirst();
Optional findAny();findFirst返回的是Stream中的第一个元素,而findAny则是随机返回Stream中的任意一个元素,在串行流中二没有区别,但在并行流中是有区别的。
10、anyMatch allMatch noneMatch
| anyMatch | 任意一个元素成功,返回true |
| allMatch | 所有的都是,返回true |
| noneMatch | 所有的都不是,返回true |
List<String> strs = Arrays.asList("a", "a", "a", "a", "b");
boolean aa = strs.stream().anyMatch(str -> str.equals("a"));
boolean bb = strs.stream().allMatch(str -> str.equals("a"));
boolean cc = strs.stream().noneMatch(str -> str.equals("a"));
long count = strs.stream().filter(str -> str.equals("a")).count();
//:直接通过BinaryOperator操作,返回值是Optional
public static <T> Collector<T, ?, Optional<T>> reducing(BinaryOperator<T> op);
//预定默认值,然后通过BinaryOperator操作
public static <T> Collector<T, ?, T> reducing(T identity, BinaryOperator<T> op);
//预定默认值,通过Function操作元素,然后通过BinaryOperator操作
<U> U reduce(U identity, BiFunction<U, ? super T, U> accumulator, BinaryOperator<U> combiner)| identity | 合并标识值(因子),它将参与累加函数和合并函数的运算(即提供一个默认值,在流为空时返回该值,当流不为空时,该值作为起始值,参与每一次累加或合并计算) |
| accumulator | 累加函数(将流元素和identity进行累加,流元素可以不与identity相同,但是在累加函数中,需要确保返回的值类型与identity相同) |
| combiner | 合并函数(合并多个标识值,与collect方法的combiner参数原理类似,都是用于多线程时的合并策略) |
// 合并所有姓名
String reduce = students.stream().reduce(new StringBuffer(), (result, student) -> result.append(student.getName()), (r1, r2) -> r1.append(r2.toString())).toString();
// 简单写法,通过map和reduce操作的显式组合,能更简单的表示
Optional<String> reduce1 = students.stream().map(Student::getName).reduce(String::concat);
// 当然如果只是简单的字符串拼接,完全可以直接使用Collectors.joining的连接函数来实现
String reduce2 = students.stream().map(Student::getName).collect(Collectors.joining(","))
Stream skip(long n)用于跳过流中的前N个元素,并返回一个新的流。它接受一个long类型的参数,表示要跳过的元素数量。
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
List<Integer> result = numbers.stream()
.skip(2)
.collect(Collectors.toList());
// 输出结果为 [3, 4, 5]如果我们需要在流式操作中查看某个环节的元素情况,或者修改流中的某个数据项,就可以通过peek检视元素。
Stream peek(Consumer<? super T> action)// 检视元素
List<String> peek = students.stream()
.filter(s -> s.getScore() > 60)
.peek(System.out::println)
// peek还可以用来修改元素内容
//.peek(s -> s.setScore(60))
.map(Student::getName)
.peek(System.out::println)
.collect(Collectors.toList());
System.out.println(peek);
Collector<T, ?, M> groupingBy(Function<? super T, ? extends K> classifier, Supplier<M> mapFactory, Collector<? super T, A, D> downstream)| classifier | 提供一个方法,该方法的返回值是键值对的键 |
| mapFactory | 提供一个容器初始化方法,用于创建新的Map容器 |
| downstream | 同一分组的合并方法,将同一个类型合并为指定类型,该方法返回的是键值对的值 |
// 将不同课程的学生进行分类
HashMap<String, List<Student>> groupByCourse = (HashMap<String, List<Student>>)students.stream()
.collect(Collectors.groupingBy(Student::getCourse));
// 上面的方法中,最终返回默认是HashMap,键值对中的值默认是ArrayList,可以通过下面的方法自定义返回结果、值的类型
HashMap<String, List<Student>> groupByCourse1 = students.stream()
.collect(Collectors.groupingBy(Student::getCourse, HashMap::new, Collectors.toList()));
// 增加映射功能,将值设置为名字
HashMap<String, List<String>> groupMapping = students.stream()
.collect(Collectors.groupingBy(Student::getCourse, HashMap::new, Collectors.mapping(Student::getName, Collectors.toList())));
// 增加合并函数,计算每科总分
HashMap<String, Integer> groupCalcSum = students.stream()
.collect(Collectors.groupingBy(Student::getCourse, HashMap::new, Collectors.reducing(0, Student::getScore, Integer::sum)));
// 增加平均值计算
HashMap<String, Double> groupCalcAverage = students.stream()
.collect(Collectors.groupingBy(Student::getCourse, HashMap::new, Collectors.averagingDouble(Student::getScore)));
System.out.println(groupByCourse);
System.out.println(groupMapping);
System.out.println(groupCalcSum);
System.out.println(groupCalcAverage);
Stream distinct()// 去重 统计所有科目
List<String> courses = students.stream().map(Student::getCourse).distinct().collect(Collectors.toList());
System.out.println(courses);