数据库设计的基本步骤
阅读数:234 评论数:0
跳转到新版页面分类
数据库
正文
通常分为六个阶段:
一、需求分析
需求分析不仅要明确用户的各种需求,还要充分考虑今后可能的扩充与改变。常用结构化分析方法(SA, Structured Analysis),即自上而下,逐层分解的方式分析系统。
1、数据流图 (Data Flow Diagram, DFD)
数据流图表达了数据和处理过程的关系,在SA方法中,处理过程的处理逻辑常常借助判定表或判定树来描述。在处理功能逐步分解的同时,系统中的数据也逐级分解,形成若干层次的数据流图。
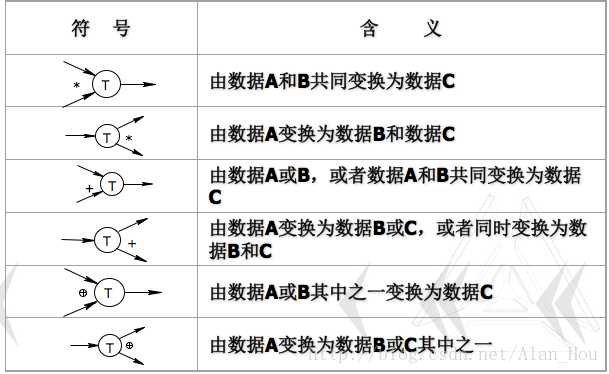
(1)基本的图形符号:

(2)加工中常用的关系符号表示
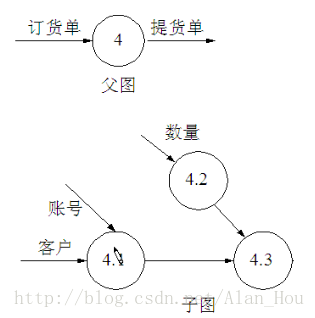
(3)子图的输入输出流同父图对应加工的输入输出数据流必须一致。
错误的数据流图:
正确的数据流图:
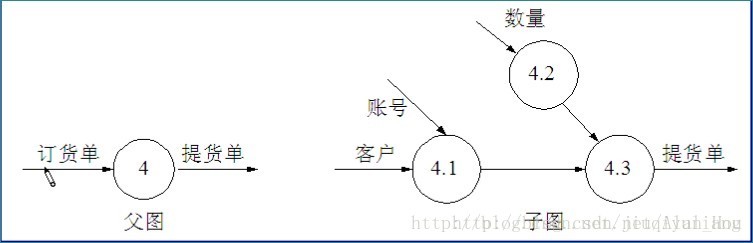
(4)外部实体与外部实体之间不存在数据流

(5)外部实体与数据存储之间不存在数据流
(6)数据存储与数据存储之间不存在数据流

(7)数据流与加工有关,且必须经过加工。
示例:
(1)项层图:对整个系统的抽象描述,只包括外部实体、加工和数据流。
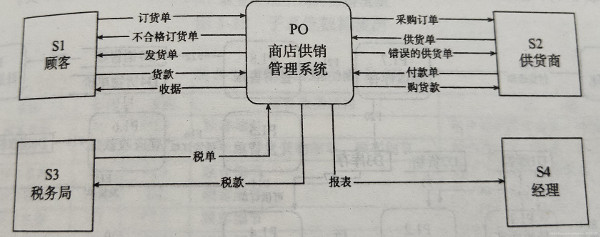
(2)分解系统,增加数据存储和对加工、外部实体的编号

(3)进一步分解
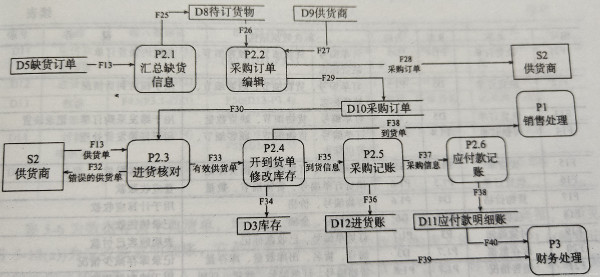
2、数据字典
数据流图描写叙述了系统的分解。但没有对图中各成分进行说明。数据字典是对数据流图中出现的全部被命名的图形元素在数据字典中作为一个词条加以定义,使每一个图形元素的名称都有一个确切的解释。

有4种类型的条目:
(1)数据项条目:通常为数据项的值类型、取值范围等。
| 编号 | 名称 | 类型 | 长度 | 说明 | 备注 |
|---|---|---|---|---|---|
| I1-01 | 用户密码 | 字符型 | 50 | 用户账号密码 |
(2)数据流条目:数据流的定义,列出该数据流的各组成数据项。
| 编号 | 名称 | 来源 | 去向 | 所含数据结构 | 说明 |
|---|---|---|---|---|---|
| F1 | 用户信息 | S1 | D1 | 用户细节 | 用户提交注册表单的用户数据 |
(3)文件条目:对文件的定义
| 编号 | 名称 | 插入数据流 | 输出数据流 | 内容 | 说明 |
|---|---|---|---|---|---|
| D1 | 用户 | F1(S1-D1) | F2(D1-S2) | 编号、细节 | 用于存储有关用户的信息 |
(4)加工条目:对每一个不能再分解的加工做说明,包含加工的激发条件、加工的逻辑、优先级等。
| 编号 | 名称 | 来源 | 处理逻辑概括 | 输出数据流 | 说明 |
|---|---|---|---|---|---|
| P1 | 登录用户数据 | F1 | 读入用户数据,写入用户文件中去 | F2 |
二、概念结构设计
通过对用户需求进行综合,归纳抽象形成一个独立于具体DBMS的概念模型,描述概念模型较理想的工具是E-R图。
E-R图中的冲突主要有三类:属性冲突、命名冲突、结构冲突。
三、逻辑结构设计
将概念结构转换为某个DBMS所支持的数据模型,并进行优化。(三大范式)
四、数据库物理设计
为逻辑结构选取一个最适合的物理结构(包括存储结构和存取方法),常用的存取方法有三类:1、索引方法,主要是B+树索引方法。2、聚簇方法(Clustering)。3、hash方法。
五、数据库的实施
建立数据库,编制和调试应用程序,组织数据入库,并进行试运行。
六、数据库运行与维护
数据库应用系统经过试运行后,即可投入正式运行,在数据库系统运行过程中必须不断地对其进行评价、调整、修改。