常见数据库
阅读数:67 评论数:0
跳转到新版页面分类
数据库
正文
传统的关系数据库大家都非常熟悉,这里不再赘述。
一、Columnar Database(列式数据库)
在传统的行式关系数据库中,因为数据是按行进行存储的,所以可以方便地进行数据的插入、删除及修改等更新操作,CPU只要进行一次寻址操作,就可以完成这些操作,所以行式数据库非常适用于需要频繁进行更新的数据库系统。
列式数据库的数据是按列存储的,并且每一列单独存放。只访问查询涉及的列,能大大降低系统IO。每一列可以由一个线程来处理,使查询的并发处理更容易。每列的数据类型一致,数据特征相似,可以方便地进行压缩。
1、优势
(1)当我们执行一个SQL语句时,它可以外将SQL语句分解为若干个可独立执行的、基于列的原子操作,列式数据库只需将涉及的到的列读入内存或高速缓存即可,大大节省了I/O带宽。
(2)由于数据都以列的形式存储,所以在SQL语句执行过程中,节省了行数据库中映射(Projection)运算的开销。
(3)同一个存储单元中的数据具有相同的数据类型,因此这些数据具有相同的特征,可以进行高效的压缩。
(4)由于在列式数据库中可以进行轻量的压缩,即可以在不解压的情况下直接对压缩态的数据进行操作,因此它的查询效率高于行式数据库。
2、缺点
(1)增加了磁盘寻址的时间。当并行读取多列时,需要从磁盘读取多个数据块的数据,这种代价可以通过增加预取数据的磁盘空间得到降低。
(2)增加了插入数据所用的开销。在列式数据库进行插入操作,需要寻找每个属性列的位置,其执行效率非常低,这种开销可以通过批量进行插入数据来予以降低。
(3)增加了元组重构的代价。为了对外提供一个标准的关系数据库接口,如JDBC,必须的查询计划中将不同属性列重组成元组,虽然该操作可以在内存中进行,但是执行该操作所花费的CPU代价非常高。在通常情况下,可以采用延迟物化技术降低该操作的代价。
3、关键技术
(1)数据压缩技术
消零或空格符法(Null Supression)、字典编码算法(Dictionary Encoding)、行程编码算法(Run-length Encoding)、位向量算法(Bit-Vector Encoding)、Lempel-Ziv算法(Lempel-Ziv Encoding)
(2)延迟物化
它在执行计划中用位图来标识行的位置,直到使用属性时再取实际相应列的值,避免了数据不停传递的开销。对列数据库,查询时只要读取那些与之相关的列,按照它们的成分属性构造数据组,只对要取的行执行正常的行数据库的相应操作。
(3)成组迭代
对一个具体的查询,在列数据库里,只要去读同一列值的块。如果列被设定为固定的宽度,则这些值可以直接被推荐为一个数组。
(4)查询优化技术
基于行存储的关系型数据库在查询数据时,不能只读取部分列,所有列都必须读取到内存中然后再去年不需要的列。而基于列存储的数据库可以按需读取列。
(5)稀疏索引技术
基于列式存储的数据库所建立的索引是稀疏的,列值已被排序存储,索引只建立到数据块级,当数据查询通过索引定位到数据块后,就可以使用二分法进行查询。
二、Key-value Database(键值数据库)
主要以键值对为基本的数据结构来表示和存储数据。
虽然键值数据库的种类很多,但底层的存储结构大致类似,主要分为两种:B+tree结构和日志结构合并树(Log-structured Merge-tree,LSM-tree)。B+tree具有很好的读性能,包括单点查询和范围查询,但是随着数据的不断写入和删除等操作,树结点在外存中呈现随机分布,导致了大量的随机写,然而,机械硬盘和固态硬盘等外存设备的随机写性能都不太好,所以B+tree并不适合写密集的场景。而LSM-tree具有优秀的写入性能。
1、LSM-tree
它是一种采用层次结构进行组织数据的索引结构。其核心思想是通过异步更新以及周期性的合并操作,将随机写转化为顺序写。
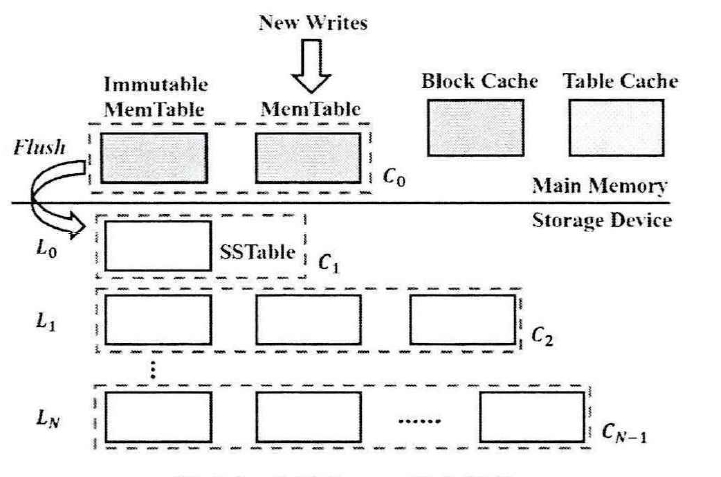
LSM-tree的数据结构主要分为两个部分:内存结构和外存结构。
内存结构主要包括MemTable、Immutable MemTable、Table Cache、Block Cache。
(1)MemTable
该结构一般采用有序的索引结构,例如:跳表(Skip-lists)或者树形结构(B+tree)。写入的数据首先会被存储到该结构中,当Memtable的大小超过设定的阈值时,MemTable会改名为Immutable MemTable并停止接受新来的数据。此时,LSM-Tree会生成一个新的MemTable用于存储之后的数据。
(2)Table Cache
该结构的主要用于缓存SSTable文件中的索引块和元数据,包括布隆过滤器(Bloom Filter)。在进行查询 操作时,我们需要通过Table Cache来获取目标SSTable文件的索引块。
(3)Block Cache
该结构用于缓存SSTable文件中的数据块。由于用户的访问具有一定的局部性,因此,缓存频繁访问的数据可以有效减少I/O开销,提升系统性能。然而Block Cache会受合并操作影响,存在缓存块失效等问题。
外存结构主要包括SSTable文件、Manifest文件、WAL文件(Write-Ahead Logging)
(1)SSTable
该结构是由数据块、索引块和Footer块组成。在SSTable中,数据块内的数据是有序的,并且数据块和数据块之间也是有序的。索引块存储的是每个数据块中的最大值,用于定位数据块,Footer块存储布隆过滤器、校验信息、索引块的相关今天处,包括位置和大小。
(2)WAL
该结构用于保证内存数据的持久性。数据写入MemTable之前,会先写入到WAL中保证持久性。因此,掉电时WAL可以用来恢复驻留在MemTable和Immutable Memtable中的数据。当Imuutable Memtable成功写入磁盘后,对应的WAL也会被删除。
2、写入流程
我们首先将数据写入Memtable中并同步到WAL保护持久化。当Memtable的容量到达阈值时,会转变为Immutable Memtable并且触发Flush操作。Flush操作会将数据写入到磁盘中,形成SSTable文件,与此同时删除对应的WAL文件。SSTable文件首先会进入L0层,当L0层的容量超过设定的阈值时,数据会通过合并操作向下移动,进入到L1层,并以此类推。
3、读取流程
我们首先查询内存结构,即Memtable和Immutable Memtable,如果存在目标key就立即返回。接着,我们查询外存结构。我们依次遍历L0层到LN层,直到找到目标的key或者返回未找到。在L0中,由于SSTable的范围相互重叠,因此我们需要依次查找最新的文件到最旧的文件。对于其他层,SSTable文件的范围互不重叠,因此我们只需要查询一个文件。当确定目标SSTable文件时,我们首先通过Table Cache获取该文件的索引块和布隆过滤器。接着,我们通过布隆过滤器判断目标数据是否存在。如果存在,我们将通过索引块定位到SSTable中的数据块并通过Block Cache进行获取,最后,通过二分查找从数据块中读取目标数据。
三、NewSQL Database
对于所有使用SQL的人员来说,并不想放弃SQL转而学习其他没有形成体系的语言,在这种情况下,出现 了基于SQL-over-NoSQL的NewSQL。其底层采用NoSQL的架构设计,提供集群的可扩展性的数据存储保障,上层支持SQL查询及SQL处理。这里不得不提的就是国产的TiDB。
NewSQL的设计的目标是成为一个Hybrid Transaction and Analytical Process(HTAP)的数据库,能够同时处理事务和分析的处理请求。
1、SQL的处理过程
在传统的关系数据库中,一条SQL语句的执行可以大致分为以下5个阶段:
(1)SQL输入
(2)语法分析,得到语法树
(3)语义检查
(4)查询优化。这部分主要包含两项工作,一是逻辑优化,二是物理优化。其中逻辑优化主要是根据关系代数,将语法受到惩罚哟在关系代数语法树。物理优化主要是对连接顺序进行调整。
(5)查询执行
四、Graph Database(图形数据库)
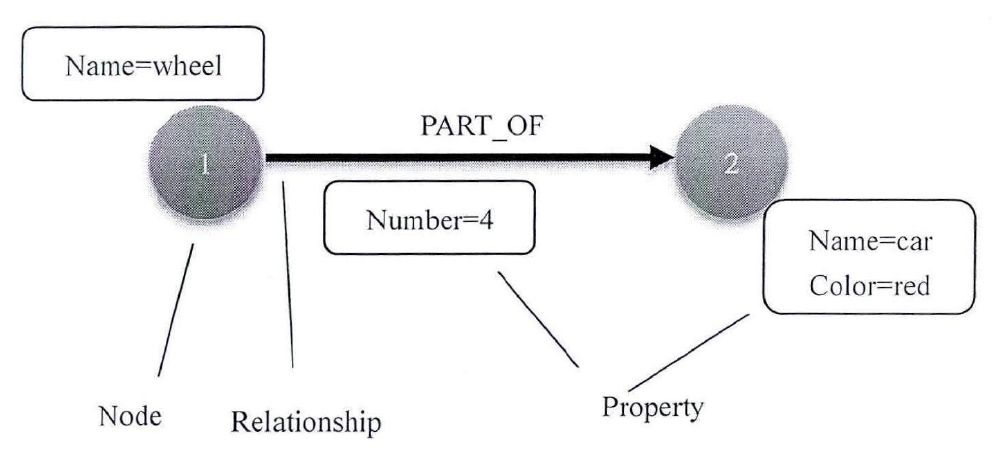
图形数据库就是将数据存储在图结构中。图形数据库可以看作是结点与关系的集合,数据存储的重析目的是为了检索,图的查找与搜索可以通过遍历算法完成。
它主要包括三种基本元素:节点(Node)、关系(Relationship)、属性(Property)。
五、Document Database(文档数据库)
概括的说,文档数据库是一个存储和管理大量结构化文档的数据库系统,它仅提供对文档的表达、组织、存储和访问功能,还可以提供诸如文本挖掘、自动文摘等文档的深度处理功能。
文档数据库管理的对象是文档,按照文档的颗粒度大小,可以外将文档分为三层视图:线性文本、结构文本和文本对象。

根据文档的三层视图,文档数据库系统结构也可划分为三个层次:
(1)线性文本层
将文档解释为无结构的字符流,对文档建立全文索引,用户可以通过全文索引对文档库进行全文检索。
(2)结构文本层
将文档解释为按照某种结构组织的文本集,对文档建立结构索引,向下可以利用全全文索引的功能,向上为提供结构化检索功能。
(3)文本对象层
将文档解释为一个独立性、封装性的文本对象,具有可访问的属性集合。
六、Time-series Database(时序数据库)
目标是应对时序数据的存储和查询,所谓时序数据即以时间顺序作为组织形式的数据。时序数据结构并不复杂,其典型特点是产生的频率快、严重依赖于采集时间。
1、分布式存储
分布式数据库有两种分片策略(sharding):范围分片(range sharding)和哈希分片(hash sharding)。
对于时序数据库来说,基于时间的范围分片是合理的。但如果仅仅使用时间分片,会有写入存在热点的问题。所以可以使用哈希进行再次分区。
2、LSM-Tree
3、数据压缩
(1)时间戳压缩:delta-of-delta算法。
(2)浮点数的压缩:如Facebook的Gotilla paper中的思想编码。
(3)整数压缩:ZigZag编码、simple8b编码
(4)布尔压缩: 使用简单的位打包策略进行编码。
(5)字符串压缩:Snappy压缩
七、Spatial Database(空间数据库)
空间数据库的五大核心技术分别为:(1)空间概念模型(2)空间数据类型与操作(3)空间查询语言(4)空间操作算法(5)空间索引访问方法
空间数据库是地理信息系统的核心。
八、Object-oriented Database(面向对象数据库)
面向对象=对象+分类+继承+消息。其中对象指一组属性及这组属性上传用操作的封装体。类是一组具有相属性和操作的对象描述。继承是类之间一种基本关系,指某个类的层次关联中不同类共享属性和操作的机制。消息是对象间通信的手段。